Lesson 2: Visualizing Data Using ggplot2
Segment 1: Introduction
In data analysis more than anything, a picture really is worth a thousand words. When you start analyzing data in R, your first step shouldn't be to run a complex statistical test: first, you should visualize your data in a graph. This lets you understand the basic nature of the data, so that you know what tests you can perform, and where you should focus your analysis. I'm David Robinson, and in this lesson we'll introduce you to ggplot2, a powerful R package that produces data visualizations easily and intuitively. We will assume you are moderately familiar with basic concepts in R, including variables and functions, and with RStudio, the integrated development environment for programming in R.
So, ggplot2 is a third party package: that means it's code that doesn't come built into the language. This means you have to install it.
You can do that with one line of R code here in your interactive terminal, which is:
install.packages("ggplot2")and hit return. Or you can go to the Tools->Install Packages menu, where here you type "ggplot2" and hit install.
Each time you reopen R, you need to load the library using the library function before you use it. So here that's:
library("ggplot2")Now we're ready to use it. ggplot2 comes with some data available to use as a demonstration: particularly, the "diamonds" dataset, containing information about several attributes of 54000 diamonds. We can access it using the data function:
data("diamonds")See that we've added "diamonds" to our global environment. Once we've loaded the diamonds dataset, we can view it using View:
View(diamonds)Here we have a view of it kind of like a spreadsheet. Here we have the carat: that's the weight of the diamond; and the cut, color and clarity: each of these are measuring something about the quality of the diamond in various levels. And then we have other attributes including the price of the diamond. You can find out what each of these mean using the "help" function:
help(diamonds)Here we get a description of the diamonds dataset, and the details about each of the columns.
Segment 2: Introduction to ggplot2
Let's say that we as scientists are interested in understanding the relationship between those attributes. For example, how does weight, in carats, affect the price? Or how does the quality of the color, or of the diamond's clarity, affect the price? These kinds of questions, where we're looking for interesting relationships among attributes using the observations we have, are common, almost universal, across data analysis.
One common visualization for determining the relationship between attributes is a scatter plot, where each diamond will be represented by one point. This is the point where as graphers, we have to make a few decisions. Let's talk about "aesthetics."
An "aesthetic" is a dimension of a graph that we can perceive visually: the simplest example being the x and y axes. When we make a scatterplot, we choose one attribute to assign to the x axis, and one attribute to assign to the y axis.
Other aesthetics we can use in a scatter plot are the color, size, and shape of the points in the graph: each of these aesthetics lets us communicate some dimension of the data, and understand complex relationships between them.
As an example, let's use ggplot2 to create a scatterplot where we put carat, or weight, on the x axis and price, in dollars, on the y axis. So now we make a ggplot2 call. We start with:
ggplot(diamonds, aes(x=carat, y=price)) + geom_point()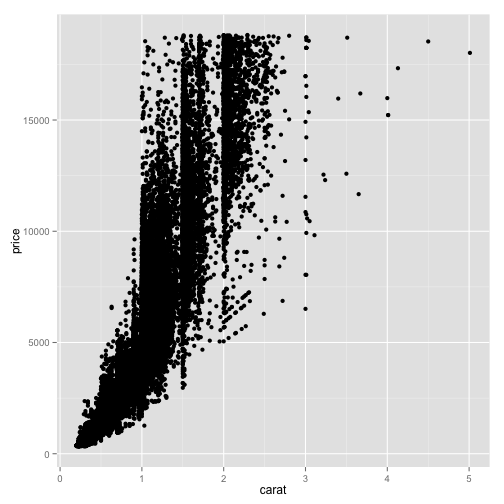
Now, there are three parts to a ggplot2 graph. The first is the data we'll be graphing. In this case, we are plotting the diamonds data frame, so we type "diamonds". Second, we show the mapping of aesthetics to the attributes we'll be plotting. We type aes- meaning aesthetics- then open parentheses, and now our assignments: we say "x=carat", saying we want to put carat on the x-axis, then "y=price", saying what we want to put on the y-axis.
Now that we've defined the structure of our graph, we are going to add a "layer" to it: that is, define what time of graph it is. In this case, we want to make a scatter plot: the name for that layer is geom_point. "geom" is a typical start for each of these layers. Now we've defined our graph, and hit return, and we see our scatter plot.
See that we've placed "carat" on the x axis, and "price" on the y-axis. Every one of these points represents one row in our data frame: that is, one diamond. We've now communicated a relationship between those two attributes in the dataset: as weight increases, price increases.
Now, this plot shows two aesthetics- weight and price- but there are many other attributes of the data we can communicate. For example, we might want to see how the quality of the cut, or the color, or the clarity, affects the price. Each of those variables is a factor: that means each value belongs to one of a finite number of categories. We can add this using another aesthetic, for example, the color of the points:
To add an aesthetic, we can hit the up arrow to get to our previous line, and then add into the aes call of the aesthetic, "color=clarity", using clarity, which is a measure of the clarity of each diamond, to color our points. We hit return:
ggplot(diamonds, aes(x=carat, y=price, color=clarity)) + geom_point()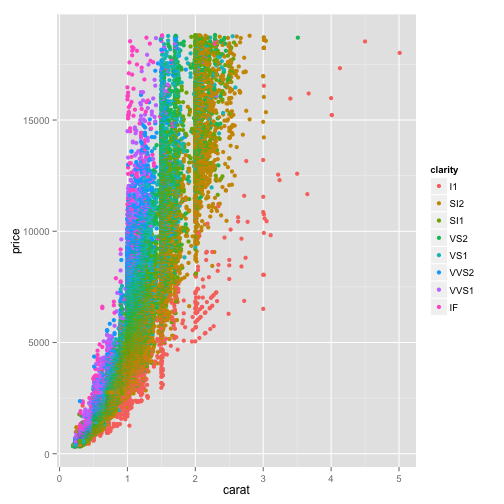
Now every point is colored according to the quality of the clarity of each diamond. Notice that it created a legend on the right side. You can see that some of the lighter diamonds are more expensive if they have a high clarity rating, and conversely that some of the heavier diamonds aren't as expensive for having a low clarity rating. This is what leads to this rainbow pattern.
If we would rather see how the quality of the color or cut of the diamond affects the price, we can change the aesthetic. Here in "aes" we change "clarity" to "color".
ggplot(diamonds, aes(x=carat, y=price, color=color)) + geom_point()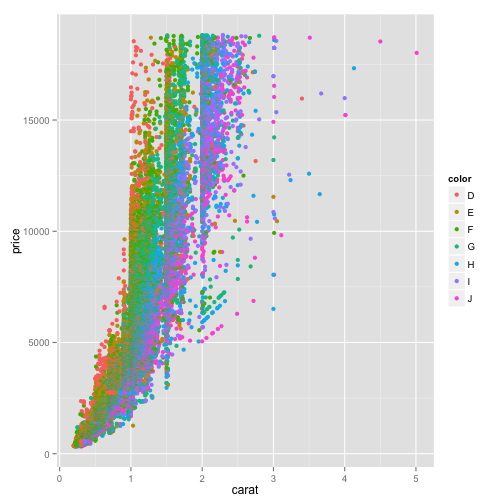
Now every item in the color legend is one of the ratings of color. Or we can change it to "cut":
ggplot(diamonds, aes(x=carat, y=price, color=cut)) + geom_point()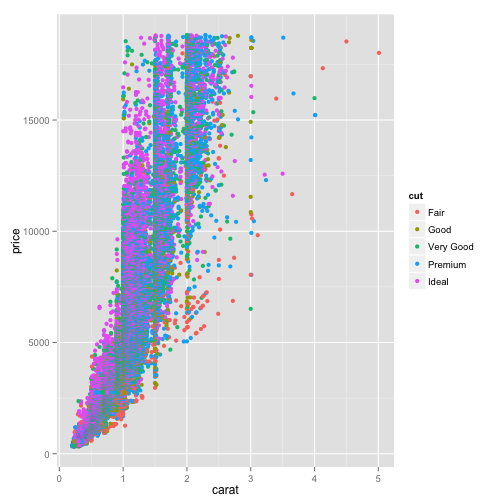
This way we can explore the relationship of each of these variables and how it affects the carat/price relationship.
Now, what if we want to see the effect of both color and cut? We can use a fourth aesthetic, such as the size of the points. So here we have color representing the clarity. Let's add another aesthetic- let's say "size=cut."
ggplot(diamonds, aes(x=carat, y=price, color=clarity, size=cut)) + geom_point()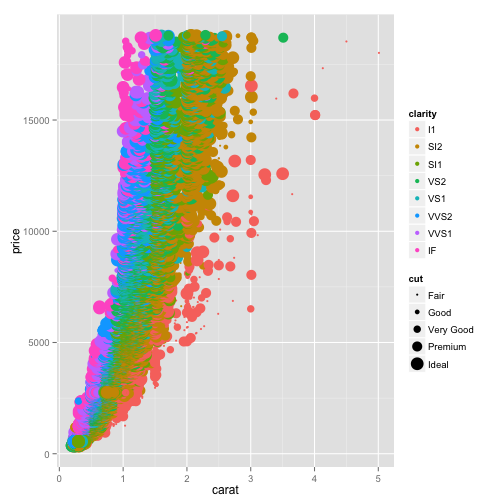
Now the size of every point is determined by the cut even while the color is still determined by the clarity. Similarly, we could use the shape to represent the cut:
ggplot(diamonds, aes(x=carat, y=price, color=clarity, shape=cut)) + geom_point()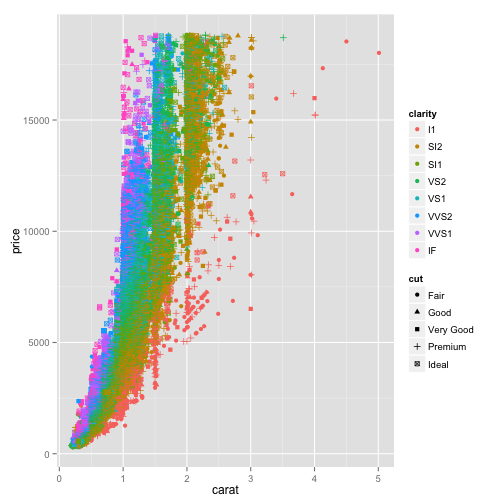
Now every shape represents a different cut of the diamond.
Now, this scatter plot is one "layer", which means we can add additional layers besides the scatter plot using the plus sign. For example, what if we want to add a smoothing curve that shows the general trend of the data? That's a layer called geom_smooth.
So let's take this plot, take out the color, and add a smoothing trend:
ggplot(diamonds, aes(x=carat, y=price)) + geom_point() + geom_smooth()## geom_smooth: method="auto" and size of largest group is >=1000, so using gam with formula: y ~ s(x, bs = "cs"). Use 'method = x' to change the smoothing method.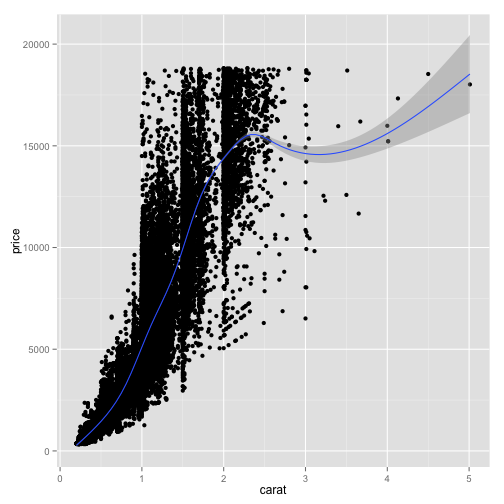
The gray area around the curve is a confidence interval, suggesting how much uncertainty there is in this smoothing curve. If we want to turn off the confidence interval, we can add an option to the geom_smooth later; specifically "se=FALSE", where "s.e." stands for "standard error."
ggplot(diamonds, aes(x=carat, y=price)) + geom_point() + geom_smooth(se=FALSE)## geom_smooth: method="auto" and size of largest group is >=1000, so using gam with formula: y ~ s(x, bs = "cs"). Use 'method = x' to change the smoothing method.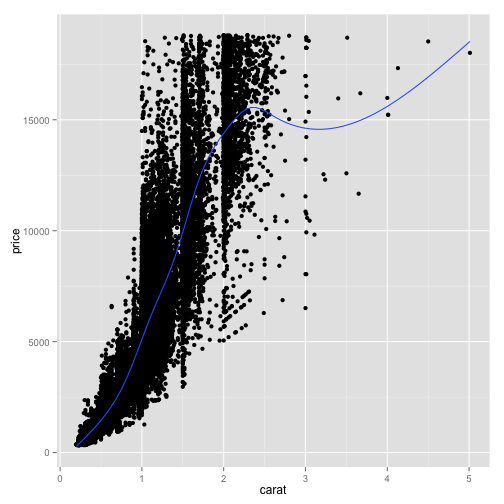
This gets rid of the gray area and now we can just see the smoothing curve.
Similarly, if we would rather show a best fit straight line rather than a curve, we can change the "method" option in the geom_smooth layer. In this case it's method="lm", where "lm" stands for "Linear model".
ggplot(diamonds, aes(x=carat, y=price)) + geom_point() + geom_smooth(se=FALSE, method="lm")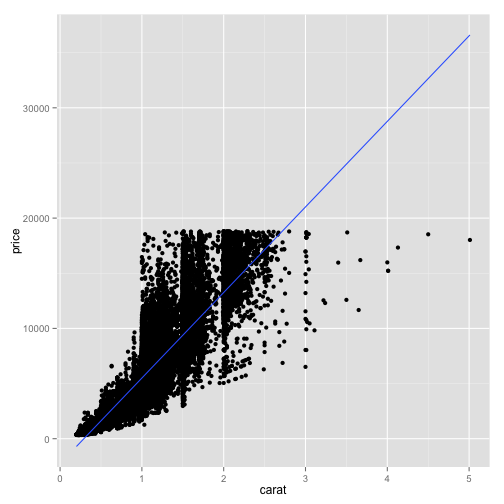
There we fit a best fit line to the relationship between carat and price with this geom_smooth layer.
If you used a color aesthetic, ggplot will create one smoothing curve for each color. For example, if we add "color=clarity":
ggplot(diamonds, aes(x=carat, y=price, color=clarity)) + geom_point() + geom_smooth(se=FALSE)## geom_smooth: method="auto" and size of largest group is >=1000, so using gam with formula: y ~ s(x, bs = "cs"). Use 'method = x' to change the smoothing method.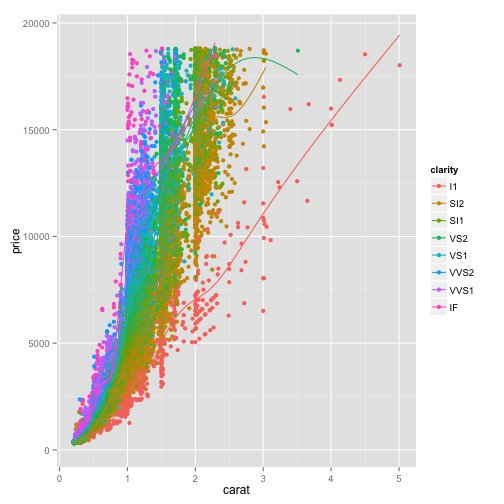
Now we see it actually fits one curve for each of these colors. This is a useful way to compare and contrast multiple trends. Note that you can show this smoothing curve layer without showing your scatter plot layer, simply by removing the geom_point() layer:
ggplot(diamonds, aes(x=carat, y=price, color=clarity)) + geom_smooth(se=FALSE)## geom_smooth: method="auto" and size of largest group is >=1000, so using gam with formula: y ~ s(x, bs = "cs"). Use 'method = x' to change the smoothing method.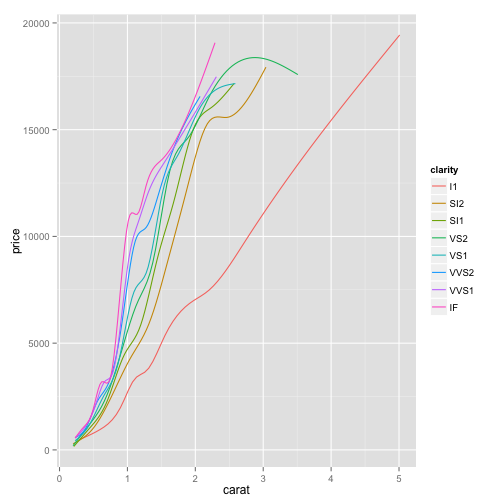
This might be a bit clearer: we can see just the fit curves without seeing the actual points.
Segment 3: Faceting and Additional Options
Another way that you can communicate information about an attribute in your data is to divide your plot up into multiple plots, one for each level, letting you view them separately. This is called "faceting", and ggplot makes it very easy with the "facet_wrap" function.
To do that, we go to a plot like this, and add "facet_wrap(". Now here we put a tilde (~), and then the attribute we would like to divide the plots by, here "clarity."
ggplot(diamonds, aes(x=carat, y=price, color=cut)) + geom_point() + facet_wrap(~ clarity)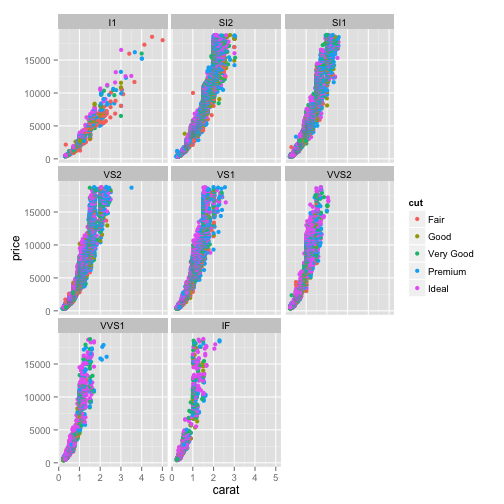
Now let's zoom in on this. You can see that now we've divided it into eight subplots, each of which has a different "clarity" value, and you can see how the trend differs between each of those subplots. We can still see that the color is representing the quality of the cut of the diamond.
You can even divide your graph based on two different attributes, such as both color and clarity, using facetgrid. In this case that would be "facetgrid(", then you put "color ~ clarity", where the tilde (~) means "explained by."
ggplot(diamonds, aes(x=carat, y=price, color=cut)) + geom_point() + facet_grid(color ~ clarity)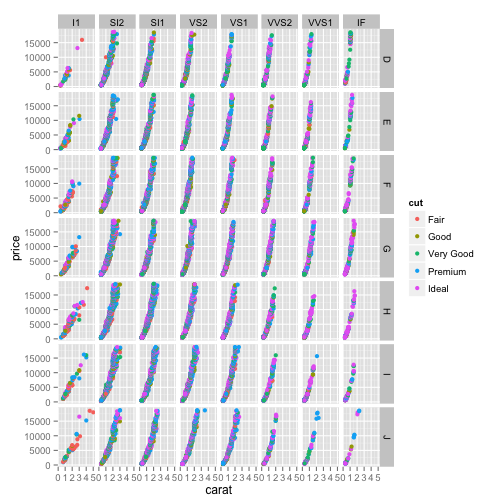
Now you can see that each column represents one of the clarity ratings, and each row represents one of the color ratings, and within the combination you can see only those that match that color and that clarity. Faceting like this gives another way to communicate the relationships within your data.
There are many other ways to customize a plot. For starters, you might want to set a title, or set the x or y axis labels manually. You change these options by adding to the end of the line of code. To set the title, you would use the ggtitle function:
ggplot(diamonds, aes(x=carat, y=price)) + geom_point() + ggtitle("My scatter plot")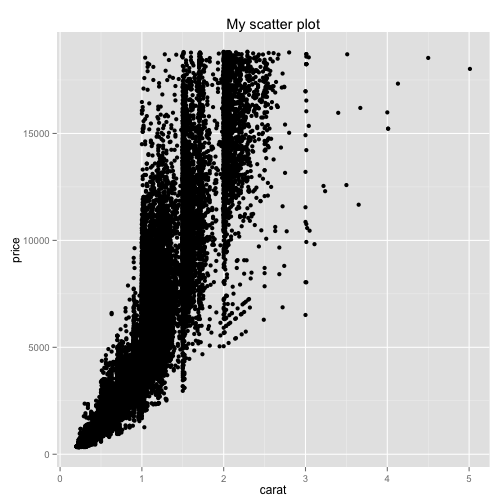
This adds a title to the top of your graph. If you'd like to change the x- or y- axis labels, you would add "xlab" for "x label", then your custom label:
ggplot(diamonds, aes(x=carat, y=price)) + geom_point() + ggtitle("My scatter plot") + xlab("Weight (carats)")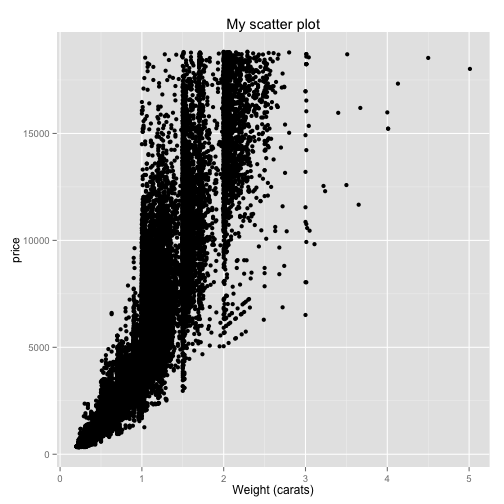
You might also want to limit the range of the x or the y axes. You can do this with the xlim or ylim options, which are also added to the end of the line. In this case, say we only want to look at the weights from 0 to 2 carats. We would do:
ggplot(diamonds, aes(x=carat, y=price)) + geom_point() + ggtitle("My scatter plot") + xlab("Weight (carats)") + xlim(0, 2)## Warning: Removed 1889 rows containing missing values (geom_point).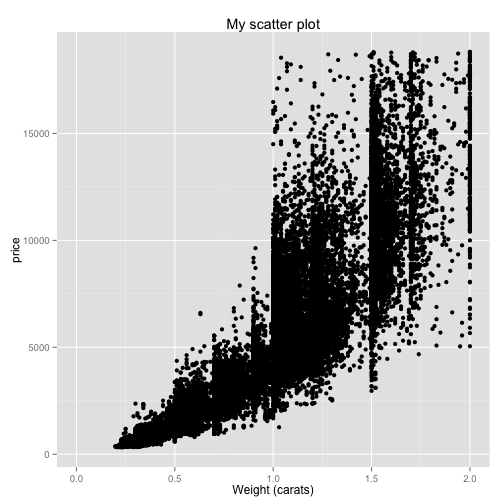
Each of these options gets added on after the last one. Now we can see that the x-axis ranges only from 0 to 2. Similarly, if we wanted to show only the y-axis from 0 to 10000, we could put
ggplot(diamonds, aes(x=carat, y=price)) + geom_point() + ggtitle("My scatter plot") + xlab("Weight (carats)") + ylim(0, 10000)## Warning: Removed 5222 rows containing missing values (geom_point).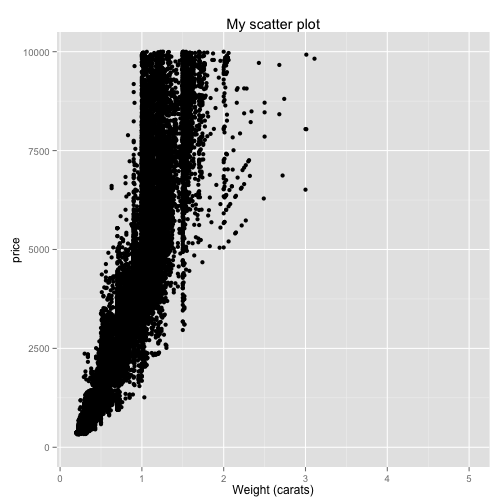
Another possibility is to put one of the axes on a log scale. You can do this with the scale_y_log10() function.
ggplot(diamonds, aes(x=carat, y=price)) + geom_point() + ggtitle("My scatter plot") + xlab("Weight (carats)") + ylim(0, 10000)## Warning: Removed 5222 rows containing missing values (geom_point).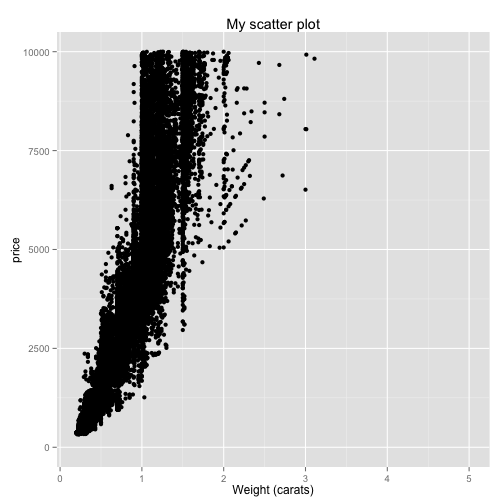
Now you've put the y-axis on a log scale.
There are many other available options and customizations: each gets added to the end of the plot just like these.
Segment 4: Histograms and Density Plots
We've seen a lot of ways to customize scatter plots. But scatter plots are just one kind of graph. Sometimes we want to look at just one dimension of our data and observe its distribution: for that, we'll use a histogram.
All you need to do to make a histogram is to change your layer from geom_point() to geom_histogram(). For example, we do
ggplot(diamonds, aes(x=price)) + geom_histogram()## stat_bin: binwidth defaulted to range/30. Use 'binwidth = x' to adjust this.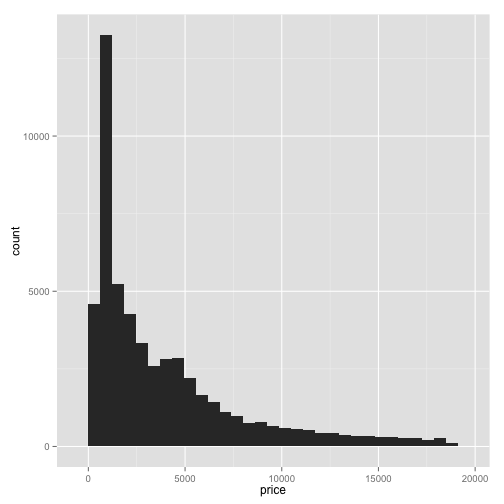
This creates a histogram. Notice that we've on the x-axis we've placed price. On the y-axis is the frequency within each bin. This is a visualization of the density of the distribution of price.
You can change the width of each bin as an option to the geom_histogram layer. You can make them wider:
ggplot(diamonds, aes(x=price)) + geom_histogram(binwidth=2000)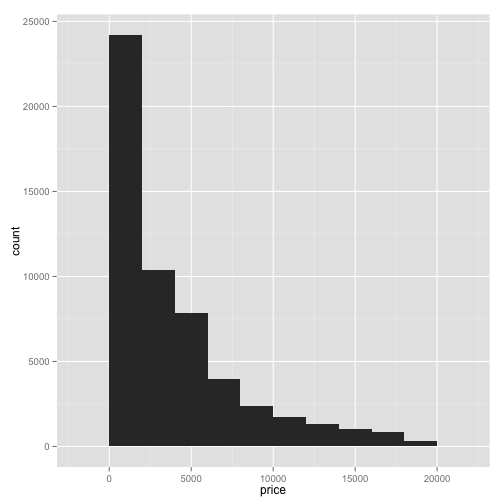
Or you can change it to be thinner:
ggplot(diamonds, aes(x=price)) + geom_histogram(binwidth=200)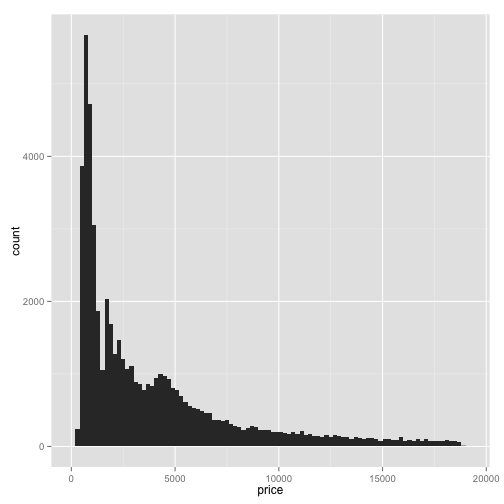
Other than that, you can do most of the same things with a histogram that you could with a scatter plot. You can again facet histograms into multiple subplots using facetwrap. For instance, take a plot and use `facetwrap, and let's divide it byclarity`:
ggplot(diamonds, aes(x=price)) + geom_histogram(binwidth=200) + facet_wrap(~ clarity)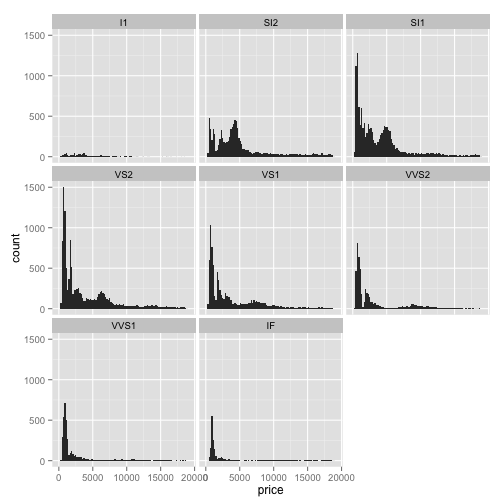
Notice that we've created 8 subplots, one for each level of clarity. Note that each subplot shares the same y axis, which might make it hard to interpret the frequencies: some subplots have far more points than others. So to free up the y axis so they can be different between the graphs, we add an argument to facetwrap. In this case, we add `scale="freey"`:
ggplot(diamonds, aes(x=price)) + geom_histogram(binwidth=200) + facet_wrap(~ clarity, scale="free_y")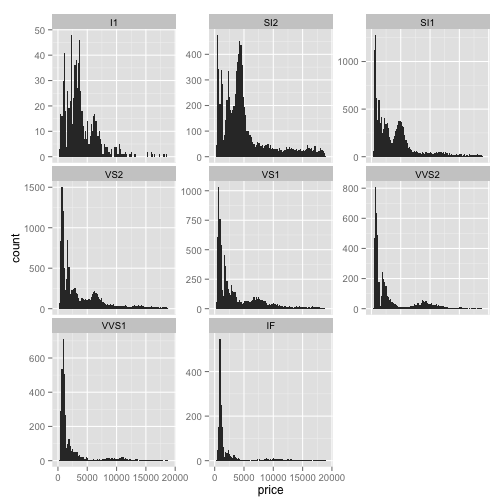
Notice that each of the subplots now has a different y-axis; some of them going up to 50, some up to 1000, depending on what is appropriate for that subplot.
Let's say you want to add another attribute to this histogram to see its effect on the density: for example, to make a stacked histogram based on the clarity attribute. Try adding the "fill" aesthetic:
ggplot(diamonds, aes(x=price, fill=clarity)) + geom_histogram()## stat_bin: binwidth defaulted to range/30. Use 'binwidth = x' to adjust this.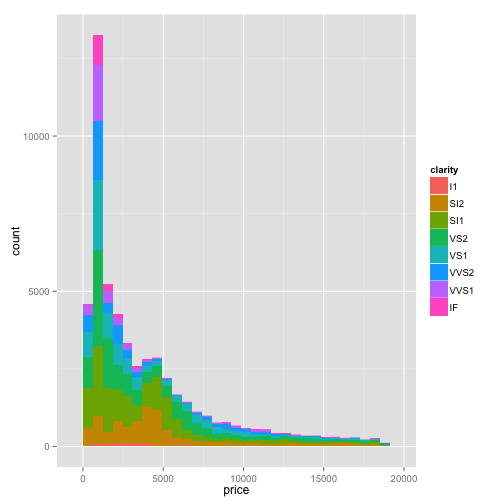
This creates a stacked histogram where each color represents the distribution of a different clarity attribute.
You could set this to any other attribute as well, for example the cut:
ggplot(diamonds, aes(x=price, fill=cut)) + geom_histogram()## stat_bin: binwidth defaulted to range/30. Use 'binwidth = x' to adjust this.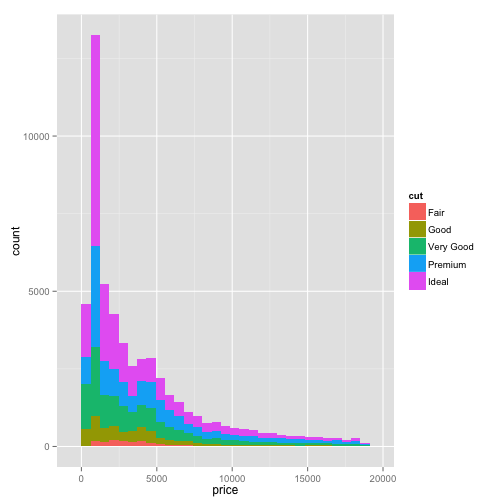
Now you can see how the distribution is composed within each of those variables.
Another way to view the distribution is as a density curve. You can do this by changing geom_histogram to geom_density. Remove the fill attribute.
ggplot(diamonds, aes(x=price)) + geom_density()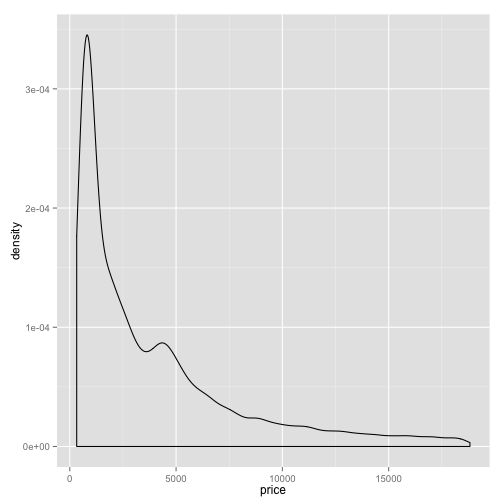
Notice it looks smoother than a histogram. If you want to divide this density curve up based on one of your attributes, you can use the color aesthetic instead of fill. For example, you can add color=cut.
ggplot(diamonds, aes(x=price, color=cut)) + geom_density()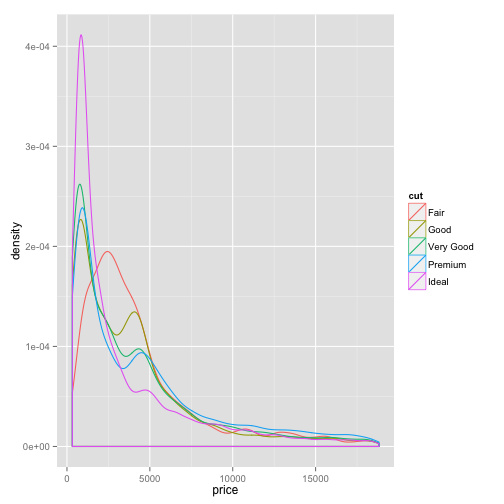
This provides a good way to compare multiple distributions.
Segment 5: Boxplots and Violin Plots
One common method in statistics for comparing multiple densities is to use a boxplot. A boxplot has two attributes: an x, which is usually a classification into categories, and y, the actual variable that you're comparing.
In this case, let's say that you want to compare the distribution of the price within each color. You would do:
ggplot(diamonds, aes(x=color, y=price)) + geom_boxplot()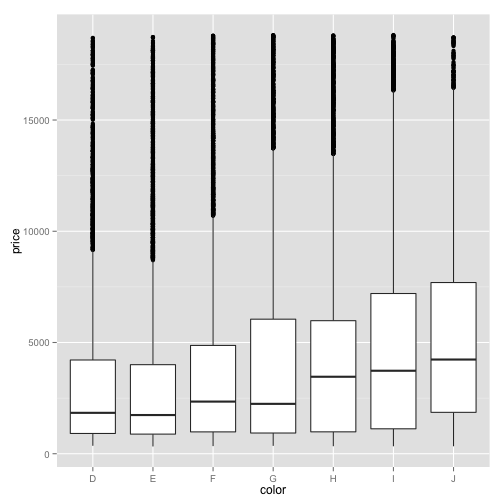
The boxplot provides some information in a compact form: you can see the median as a thick black line, the edges of the box show the 25th and 75th quantiles of the data respectively, and these points are outliers that lie far outside the expected range of the data. In this particular case, since there are a large number of outliers you might want to try putting the y-axis on a log scale. Recall that we do that by adding an option:
ggplot(diamonds, aes(x=color, y=price)) + geom_boxplot() + scale_y_log10()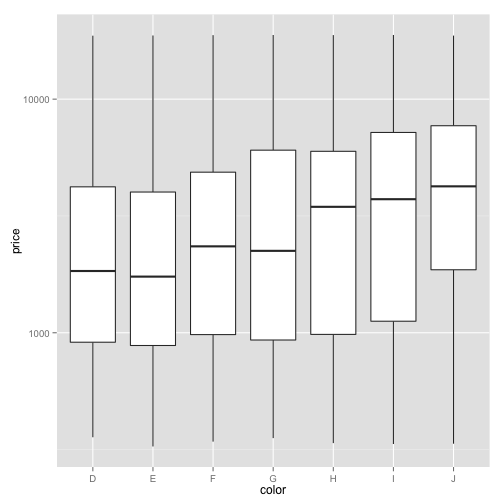
This is a better behaved boxplot that gets a better sense of how the distribution of price differs across multiple colors.
One problem with the boxplot is that it doesn't show details of the distribution besides these quantiles. This works well when the data follows a Normal distribution, or a "bell curve," but it might not work well for stranger distributions. For example, the distribution might have not one but two frequency peaks, what we call "bimodality." However strange the distribution, a box plot will always look like a square. We can instead view the distribution as a density using what's called a "violin plot". To do that, all we do is change geom_boxplot to geom_violin.
ggplot(diamonds, aes(x=color, y=price)) + geom_violin() + scale_y_log10()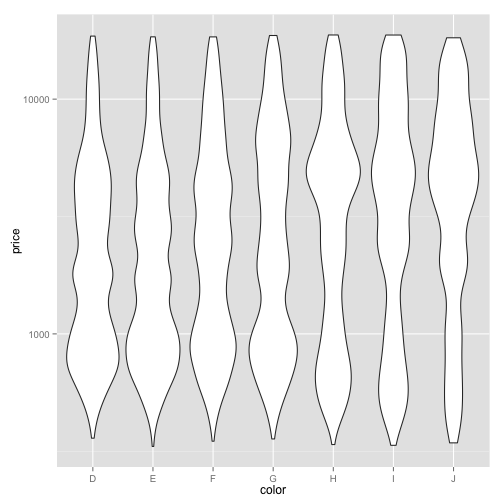
The width at each point in this violin plot represents the frequency of that price. So these bumps show the prices that are more common, and we can see that indeed within some colors there is bimodality- there are multiple points that are common- that a boxplot did not represent.
Just like in scatter plots or histograms, if we want to see whether another variable is involved, we can use facet_wrap to divide our plot into multiple subplots. For example, we could divide this into subgroups based on clarity. To do that, we would do
ggplot(diamonds, aes(x=color, y=price)) + geom_violin() + scale_y_log10() + facet_wrap(~ clarity)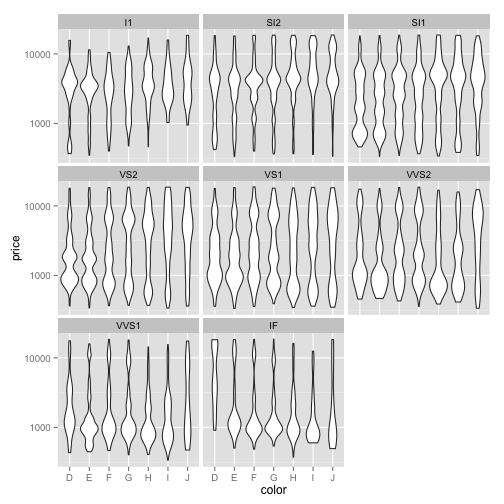
Now you can see that we've divided it into eight smaller violin plots showing the distribution within each of those levels of clarity.
Segment 6: Input- Getting Data into the Right Format
So far all of our analyses have started with a data frame: one row per observation, one column for each attribute. But let's say you have just one vector of numbers and you want to create a histogram, or you have two vectors and want to make a scatterplot. It may not be worth it to construct a data frame with those values just so you can graph it. To make your life easier, ggplot2 provides a simple way to plot one or two vectors, which is the qplot function.
Let's generate some random numbers we want to plot. The rnorm function generates random values from a normal distribution, or "bell curve." So if we create a variable x with rnorm, saying how many random values we want, for example 1000:
x = rnorm(1000)We have created a variable containing 1000 values. Here we can see:
x## [1] -0.767976 1.092880 -1.148876 -0.227929 -0.031724 1.525922
## [7] 1.956483 0.816365 -0.097223 -1.189389 0.650418 -0.272137
## [13] 1.113032 -1.250487 -0.143695 -0.080595 0.840582 -0.320572
## [19] -1.522667 0.180074 0.087707 -1.895700 1.139786 0.556740
## [25] 0.031125 -0.904617 0.129287 1.301862 -0.867835 1.191338
## [31] -0.106237 -1.431230 0.284037 -0.789191 1.065142 0.439482
## [37] 1.212021 -1.044236 -0.433373 0.938645 -0.985462 1.881374
## [43] -0.333418 -1.514220 2.073098 -0.093422 -2.182270 -1.110745
## [49] 0.125777 -0.495178 -0.552226 -0.026382 0.748899 0.096095
## [55] -1.111074 -0.431994 1.979234 0.224045 -0.600010 0.170636
## [61] -0.678995 -0.250758 0.494726 -1.951109 1.108450 -0.153137
## [67] 0.563256 0.619098 -0.168387 -1.102127 1.872808 0.144198
## [73] 1.261328 1.077896 -0.169493 -0.020381 -1.211208 -0.708169
## [79] 1.451428 0.174123 0.094639 -0.928344 0.849235 0.558727
## [85] -0.174487 -0.087892 0.814328 -0.602571 1.174918 -0.936348
## [91] 0.033781 -2.046890 -0.056894 -0.795511 1.023542 1.966396
## [97] 0.439014 0.580309 0.250758 0.860897 0.945866 -1.310817
## [103] -0.733474 -1.550747 -0.597531 -0.409337 -0.207903 -1.976501
## [109] -1.103510 0.092630 0.659819 -0.135005 -0.179216 0.464951
## [115] 0.972011 1.080596 1.428510 0.784679 -2.317085 0.490924
## [121] 0.701145 0.025214 -0.437770 0.871446 1.130811 -0.351855
## [127] -0.408936 0.532250 -2.703305 0.658913 -1.012426 -2.561438
## [133] -0.870997 -0.322174 -1.497694 0.999266 0.018884 -1.654286
## [139] -0.456806 0.981518 0.992429 -0.496719 0.443949 -0.697972
## [145] 1.297184 0.035320 -0.498795 -1.781366 1.329989 0.022711
## [151] 0.166595 -0.167127 -0.261074 -1.319557 0.386719 1.623520
## [157] 0.465675 1.570625 -0.659826 -1.187267 -0.594184 -0.084365
## [163] -0.958789 1.198785 -0.101249 1.078480 1.236419 0.523305
## [169] -0.545411 1.218834 0.679361 -0.055897 0.204121 -0.166485
## [175] 1.143245 0.314154 -1.301530 -0.174272 1.201572 -0.120748
## [181] 1.039353 -1.468683 -0.412584 0.683560 0.259569 -1.095196
## [187] -0.115487 1.658609 1.344382 -0.418018 -0.581510 -0.582983
## [193] -0.249724 -0.641890 -0.441712 -2.300156 -0.745138 -0.151615
## [199] 0.720040 1.953404 -1.266988 -0.378855 -0.071720 0.106586
## [205] 0.764706 1.190615 -0.063470 2.245822 -0.830228 1.260256
## [211] 0.309007 -0.091105 -0.953759 -0.032898 -1.106786 -0.164819
## [217] 0.947067 -0.664471 -0.463163 -0.094050 -0.067109 0.543994
## [223] -1.072875 0.313631 -1.761344 0.881058 -0.621656 0.026465
## [229] -2.442603 0.367184 0.157167 0.051670 0.367387 0.136041
## [235] 0.342042 -0.700000 -0.124437 -1.050821 -0.028073 -0.375482
## [241] -0.604072 1.742097 -0.211952 -0.292591 0.478056 1.742134
## [247] -0.176733 1.824815 0.499820 -0.903091 -0.403873 -0.365695
## [253] -1.216434 -0.472265 -0.664311 -0.330631 -1.742465 1.179543
## [259] 1.181712 -1.310821 0.304163 -0.658717 0.765355 0.327995
## [265] -0.023685 -0.300895 0.955081 -0.217568 1.059325 0.869876
## [271] 0.253146 -0.031653 0.217770 -0.862389 0.782240 -0.514901
## [277] 1.891438 1.690919 0.057017 -2.039217 1.041391 -0.149694
## [283] 0.184718 0.287652 -0.249951 -0.438700 -0.391203 -1.834560
## [289] -1.220305 0.196990 0.690956 2.658999 -1.154086 -1.483668
## [295] -0.085344 1.625332 0.152860 -0.943511 0.620347 -0.924557
## [301] 1.218137 0.731783 -1.269384 0.716081 1.668377 0.909692
## [307] 1.614011 -0.714343 -0.189806 -1.584955 -0.403276 0.470105
## [313] 0.474708 -1.628119 -0.283899 -0.909501 1.679925 1.235592
## [319] -0.413229 0.383616 0.492232 0.877651 0.673158 1.613780
## [325] -0.386630 -1.477449 -0.227330 0.961038 0.225290 -0.463753
## [331] 0.187833 -0.113936 -0.778273 0.161349 -1.019350 0.145984
## [337] 1.317119 -2.449724 -0.750742 -1.118524 1.199659 -0.701028
## [343] -0.620085 -1.611441 -1.570025 -1.283916 0.681131 -0.649543
## [349] -0.155017 0.958000 0.297795 0.139139 -0.569088 -0.154947
## [355] -0.324848 -0.289767 0.014053 -0.931720 -0.370764 -0.305153
## [361] -0.222359 -0.917417 0.955380 0.362836 0.379315 -0.222799
## [367] -1.046225 0.444673 0.593322 0.002689 0.457594 -0.544127
## [373] -0.589410 0.798049 -0.539552 -1.767267 1.187294 -0.068519
## [379] 0.609434 -2.120508 -0.927756 1.486529 -1.284556 -0.876325
## [385] -1.799913 0.191433 -1.323058 -0.575813 1.097699 -0.125402
## [391] 0.944021 0.441978 1.188122 -0.318779 0.320599 0.179449
## [397] -1.917014 0.565447 0.254044 0.120516 1.491212 -0.278233
## [403] 0.468439 -0.067155 -0.246635 1.807160 1.314761 0.731326
## [409] 1.040793 1.130478 1.413303 -2.193813 -0.726739 1.702053
## [415] -1.542970 1.468113 -0.033596 0.710999 0.260428 -0.812225
## [421] 2.624350 0.519883 0.388695 0.163236 -0.175318 -0.671686
## [427] 0.655893 0.306364 -0.357432 -0.616094 0.552909 -0.819538
## [433] 1.644679 1.032742 -0.598847 -0.870561 -1.658863 0.024206
## [439] -1.100336 -0.505527 -0.145596 0.031275 1.146919 1.047001
## [445] -0.213243 1.510653 0.380977 0.220387 0.088069 -2.347948
## [451] 0.670222 -1.386710 -1.107352 -1.901936 -0.666064 0.538182
## [457] 0.983374 -0.057773 -1.691435 -0.060551 0.940627 -0.071156
## [463] -0.342304 0.250860 1.095264 -1.598113 -0.246793 -0.059271
## [469] -1.178915 0.326530 -0.308064 0.443374 0.929823 -0.216532
## [475] -1.779098 0.490158 -1.752850 -0.860201 -2.110891 1.177634
## [481] -0.032958 -0.555839 0.816577 -0.136159 -1.144639 -0.465646
## [487] 1.784524 -0.921188 -1.390998 -0.722213 1.338275 1.103045
## [493] 0.158334 -0.933094 -1.033184 0.062241 -1.354813 0.563162
## [499] 0.337604 -0.258630 -0.580220 -0.044960 0.862166 0.284771
## [505] -0.694661 1.743320 0.453736 1.544878 0.821542 1.315577
## [511] 0.119299 -2.277188 0.110102 0.788637 0.362853 -0.226129
## [517] 1.394578 0.429123 0.706912 0.670081 -0.069334 -1.451718
## [523] -1.928327 -0.813262 0.111150 0.856797 -0.463102 -1.289876
## [529] -1.864715 1.152853 -0.116690 0.579501 0.042917 -1.159574
## [535] 0.027420 0.550619 -0.733916 0.402086 1.092806 1.505882
## [541] -0.098833 -0.331133 -0.539615 0.575437 1.342629 0.184206
## [547] -0.487567 -0.006799 0.106829 -1.513849 -1.950090 -1.126248
## [553] -0.800145 -1.119097 -2.064485 -0.576981 2.037218 1.629410
## [559] 0.285078 1.105089 0.027730 1.500103 1.567102 0.466577
## [565] 1.229376 -0.152646 -1.749257 -0.074501 1.519439 0.880122
## [571] -0.780228 -1.626332 0.803777 0.487939 -0.452620 -0.825440
## [577] 0.725347 -1.397858 1.250085 -0.783372 0.343495 -0.206959
## [583] -0.557715 1.824677 0.021530 0.874858 -0.602573 -0.097092
## [589] 0.149867 -0.423802 -1.415196 -0.097871 0.252993 -0.159764
## [595] 1.190248 0.420222 0.642267 -1.154389 0.450673 -0.274955
## [601] 2.488948 1.661032 0.559907 -0.419766 -0.108183 0.489831
## [607] -0.772067 0.671584 -0.569628 0.905747 -0.934577 -3.126333
## [613] -0.282830 -1.133741 1.690539 0.287980 0.222932 -0.038633
## [619] -0.675226 -1.237250 0.583099 -0.900579 0.456711 0.069992
## [625] -0.915928 -0.900181 1.550503 -0.626194 0.943303 -0.313196
## [631] 0.858720 -0.249685 0.651965 0.592160 -1.955672 -0.458608
## [637] 1.708815 -1.814759 0.549265 1.271201 0.919184 -1.050675
## [643] 1.667953 0.937835 -0.505635 0.393714 -0.497313 -0.662254
## [649] 0.418392 -1.297320 0.618082 -1.179734 0.567823 -1.022876
## [655] 0.953819 1.200602 0.685964 0.979194 -0.418257 0.380145
## [661] -0.990790 1.012020 -0.488494 -0.394403 -0.419530 0.074125
## [667] 0.915403 0.265436 0.007423 0.166311 -2.666158 1.054293
## [673] -0.265834 1.019103 2.153481 0.525294 -1.002855 0.365381
## [679] 0.837779 0.860247 0.324482 1.298356 0.900328 -0.334660
## [685] 0.609034 -1.247327 -0.039427 -0.700502 0.164682 -0.053718
## [691] -0.806796 -1.217276 -0.347937 0.971140 -0.442320 -0.907539
## [697] -0.690021 -0.910694 -0.289745 -0.847207 1.240562 -1.306729
## [703] -0.572492 -1.040262 0.851538 1.978968 -1.650267 0.095222
## [709] 0.184995 2.883596 -0.213680 -0.746362 -0.263310 1.163578
## [715] 0.321471 -1.318092 -0.583425 1.580847 -0.689931 0.324048
## [721] 0.446443 1.134672 -1.720660 -0.895714 0.726958 -0.747638
## [727] -1.097166 1.447968 -1.828147 -0.616760 0.753865 1.755265
## [733] 1.749078 -0.052810 -0.129634 0.303859 -1.186053 -0.712889
## [739] 0.204841 0.496668 -0.060764 0.625534 2.035650 -0.407303
## [745] 0.781652 1.288413 0.330130 1.093149 -0.271187 1.238368
## [751] 0.506686 0.883278 0.891350 -0.883244 0.432896 -1.077110
## [757] -1.267532 0.835984 0.987731 0.749318 -1.614052 0.347248
## [763] -1.365016 0.719369 0.841446 1.366950 0.514742 -1.892667
## [769] -0.027651 1.072378 1.495051 1.480751 1.348454 -0.073333
## [775] 0.887614 -0.891076 -0.117378 0.113252 1.679581 1.152863
## [781] 0.196829 0.602648 -0.225426 -1.393102 1.069235 1.421708
## [787] 1.396834 -1.042380 -1.050559 0.437160 0.609040 -0.080125
## [793] -0.160217 0.481159 -1.184874 0.171694 -0.501682 0.671438
## [799] 0.238957 -0.727557 -1.371120 0.967659 0.149266 -1.711404
## [805] 0.833710 0.497832 -0.665946 0.267378 -1.135373 2.825502
## [811] 0.918022 0.155520 -1.234455 -0.391272 -0.367801 -0.840935
## [817] -1.198968 0.229372 -1.189725 0.921702 -0.828545 0.657260
## [823] -0.125855 -0.584471 0.476609 0.304384 0.463521 -0.566284
## [829] -0.488126 -0.945729 -2.326579 0.041013 -0.111358 -0.309605
## [835] 1.162963 1.054004 0.387477 0.532450 1.262285 -1.441884
## [841] -1.079336 2.839477 0.464015 0.739432 0.464901 0.865921
## [847] 2.336025 -0.200137 -0.636474 0.217204 -0.017255 -0.132606
## [853] -1.569592 0.747592 0.379451 -0.058265 -0.061518 -0.287745
## [859] -0.236901 -1.094673 0.680016 0.742903 0.029813 0.966677
## [865] 1.394062 -0.550119 0.031291 -1.026723 0.885414 0.634024
## [871] -1.790575 1.068823 1.098732 -1.615128 -0.175365 0.297412
## [877] 0.589731 -0.926714 0.169737 1.510236 0.232797 -1.011914
## [883] -0.965625 -0.724631 0.667356 1.193168 0.573192 -1.711171
## [889] -0.549775 1.583744 0.315137 1.108349 -0.442437 0.003004
## [895] -0.012805 -1.824991 0.817208 -1.043873 -2.198068 -0.104511
## [901] -1.431259 -0.219900 -1.856196 -0.986190 0.464491 1.536385
## [907] -2.113679 0.240835 1.890646 -0.048310 0.113799 -1.052622
## [913] -0.864005 -1.212047 -0.648404 -0.355820 -1.432229 1.678210
## [919] 0.234425 0.641791 -0.616966 1.379328 -0.191650 0.961433
## [925] 0.841687 1.947768 -0.202570 -0.890680 -0.152208 1.477951
## [931] 2.086305 0.569441 -1.046112 0.796687 -1.649376 -0.151335
## [937] 0.539180 -0.670095 -0.389053 0.751170 0.854085 0.765594
## [943] -0.436655 0.487787 1.648605 1.407824 2.255959 -1.076605
## [949] -0.524487 -1.182632 0.074674 -1.221158 -1.114978 0.106289
## [955] -0.538519 -0.239299 -1.403947 0.866340 -0.400686 -0.511115
## [961] 0.266152 0.243812 1.602333 0.427074 -0.755100 0.117753
## [967] -0.013287 -1.474844 0.379072 0.398178 0.722071 0.182590
## [973] 0.053742 1.221532 1.970120 -0.158995 -0.275443 -1.710383
## [979] 0.277754 -0.470659 1.553648 -0.077211 0.480868 0.159209
## [985] 0.223879 -1.761536 0.295825 0.067536 -0.921659 0.482009
## [991] -0.768430 0.657269 -0.884369 -0.301836 -1.201564 -0.633679
## [997] -1.576791 0.238411 0.341165 -0.734252Each of these values was generated from a normal distribution.
Let's say we want to histogram those values. We can give them to the function qplot:
qplot(x)## stat_bin: binwidth defaulted to range/30. Use 'binwidth = x' to adjust this.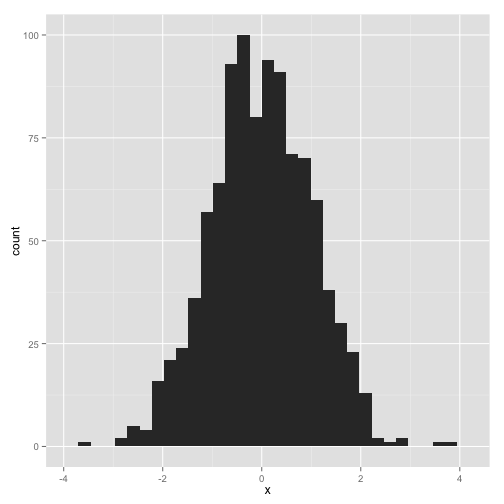
This creates a histogram without having to create a data frame or specify geom_histogram.
This shortcut also lets us set options easily. For example, we can change the binwidth of the histogram by giving the binwidth argument to qplot:
qplot(x, binwidth=1)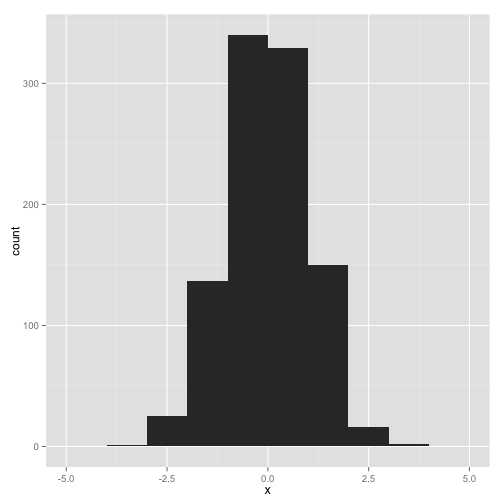
We can also set the x and y axis labels easily. We can do that either by adding the xlab and ylab options like we did before:
qplot(x, binwidth=1) + xlab("Random Variable")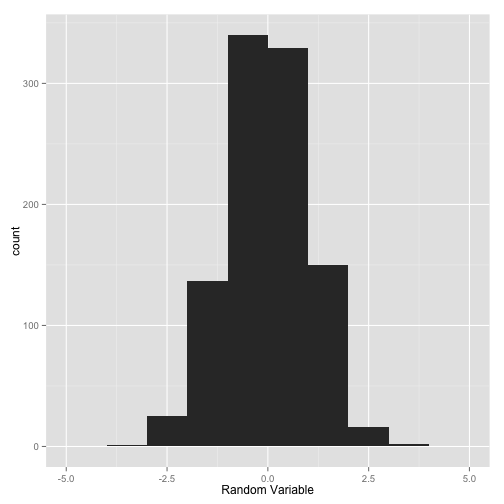
Or we can add the xlab argument to the qplot function.
qplot(x, binwidth=1, xlab="Random Variable")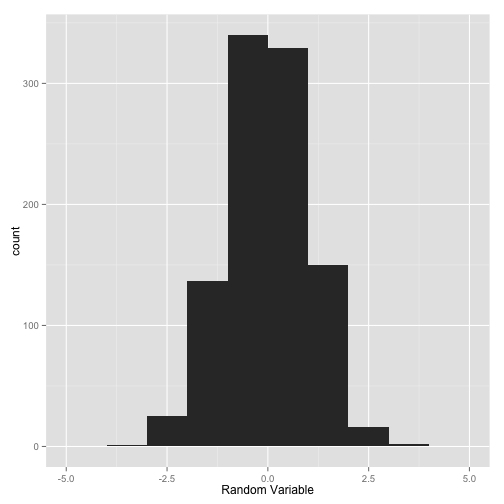
Histograms aren't the only thing we can plot with qplot. Let's create a y variable so that we can construct a scatter plot comparing x to y. Let's make y also be a random normal distribution:
y = rnorm(1000)If we want to scatterplot x vs why, we can simply give them to qplot.
qplot(x, y)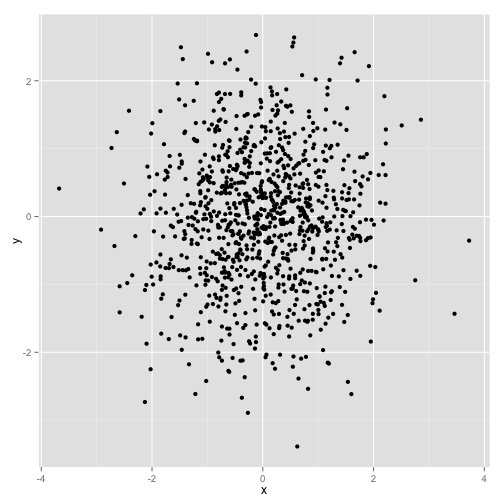
Note that we can still add layers to this basic plot just like we could to a regular ggplot call. For example, we could add a smoothing curve with the geom_smooth layer:
qplot(x, y) + geom_smooth()## geom_smooth: method="auto" and size of largest group is >=1000, so using gam with formula: y ~ s(x, bs = "cs"). Use 'method = x' to change the smoothing method.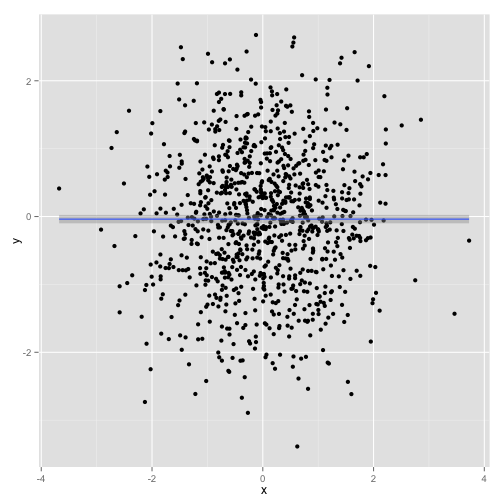
This layer ends up on top of the scatterplot created by qplot.
Now, so far we've been working with the built-in diamonds dataset. These plots were really easy because the data were given in the format of one observation per row- that is, one diamond per row- which we call "tall" format. But many datasets come in a "wide"" format: that means there is more than one observation- more than one point on your scatterplot- in each row. For example, let's look at the WorldPhones dataset, which comes built into R. Just like we did for diamonds, we use data to load it:
data("WorldPhones")You can see it got added to our global environment. You can then view it using the View function.
View(WorldPhones)You can also get more information about WorldPhones using the help function:
help(WorldPhones)This dataset shows the number of telephones, measured in thousands, in each continent in each of several years in the 1950s.
Notice that each column is one continent, and each row is one year. Now, that sounds like a reasonable way to store your data. But imagine if we want to compare increases in phone usage between continents, with time on the x axis. That means each point on our plot is going to be one continent in one year. We don't have one observation per row: we have seven! That makes it very difficult to plot using ggplot2.
Luckily, there is an easy way to turn this into tall format, called "melting" the data. To do this, we'll have to install another third party package, called reshape2. Recall that you can do this with
install.packages("reshape2")just like we did with ggplot2. Now we load the reshape2 package, with
library(reshape2)Now we can melt our dataset: that is, turn it from this wide format- many observations per row- to a tall format- one observation per row. Let's assign the new, melted data to a variable called WorldPhones.m, where m is for melted. We assign this using the melt function on the WorldPhones data.
WorldPhones.m = melt(WorldPhones)Now let's view our new, melted data.
head(WorldPhones.m)## Var1 Var2 value
## 1 1951 N.Amer 45939
## 2 1956 N.Amer 60423
## 3 1957 N.Amer 64721
## 4 1958 N.Amer 68484
## 5 1959 N.Amer 71799
## 6 1960 N.Amer 76036Notice that there are now only three columns: Var1, Var2, and value. So Var1 is year, in Var2 we see each of the continents, and value is the number of phones. What happened was that every cell- every observation- every number of phones per year per continent- in the original data got its own row in this melted data. We can see that in the year 1951, in North America, there were 45 million, 939 thousand phones. You can see the same value in our original unmelted data. So none of the data changed, it just got "reshaped".
To make the data a little more intuitive, you can change the column names. You might recall that we can do this as follows:
colnames(WorldPhones.m) = c("Year", "Continent", "Phones")So now if we view WorldPhones.m, we can see our new column names.
head(WorldPhones.m)## Year Continent Phones
## 1 1951 N.Amer 45939
## 2 1956 N.Amer 60423
## 3 1957 N.Amer 64721
## 4 1958 N.Amer 68484
## 5 1959 N.Amer 71799
## 6 1960 N.Amer 76036Now that we have our data in melted format, it is easy to create a plot with ggplot2. We go through our usual steps of a ggplot call, but this time we give it WorldPhones.m. We do:
ggplot(WorldPhones.m, aes(x=Year, y=Phones, color=Continent)) + geom_point()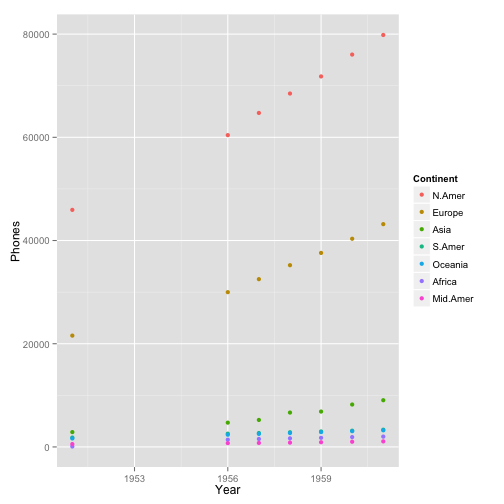
on the x-axis we're going to put the Year, so we can see how things change over time. On the y-axis we want to put the number of Phones, which is the variable we're interested in graphing. And let's color each point based on the factor of Continent. Then we'll add the geom_point layer to make this into a scatterplot.
Now we've worked with scatterplots before, but since this time what we're showing is a trend over time, it might be better to draw lines between the points in continent. This is easy: we can just change the layer to a geom_line layer.
ggplot(WorldPhones.m, aes(x=Year, y=Phones, color=Continent)) + geom_line()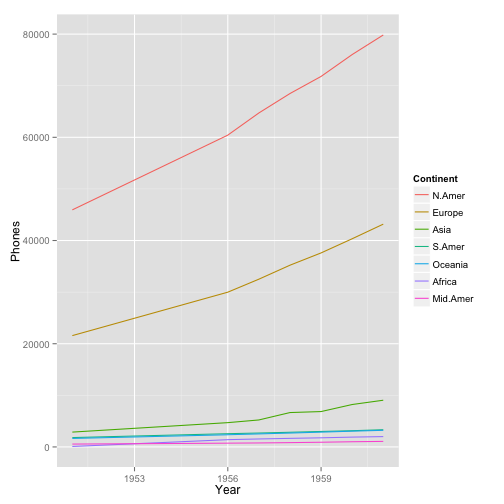
Now we have a plot of the number of phones in each continent by year. Incidentally, one might expect phone service to increase exponentially rather than linearly. Also, a lot of the values here are scrunched in the bottom of the axis. When that's the case, it's a good idea to put the y axis on a log scale. Recall that we can do that by adding scale_y_log10().
ggplot(WorldPhones.m, aes(x=Year, y=Phones, color=Continent)) + geom_line() + scale_y_log10()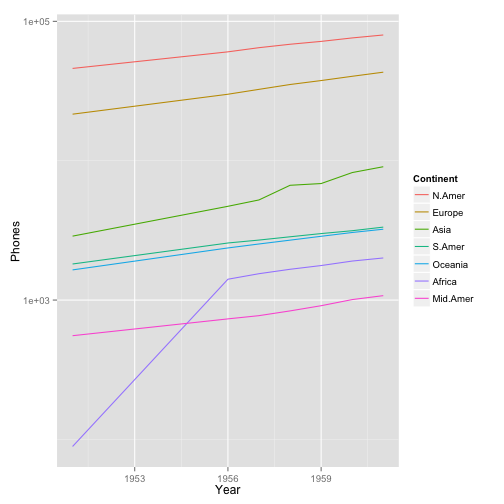
Now each of the phone trends looks linear, and we can see the lower values more clearly: for example, that Africa overtook Central America in the number of phones in the year 1956.
Notice how easy this plot was to make once we had the data in the correct format: one row for every point- that's every combination of year and continent- on our graph. So if your data's not in that format when you're starting out, melt it.
Segment 7: Output: Saving Your Plots
So you just created a great ggplot, and now you want to save it to a file, so you can email it, or add it to your paper or poster, or just look at it later. You can do this with the ggsave function.
First, let's create a scatterplot based on our diamonds data.
ggplot(diamonds, aes(x=carat, y=price)) + geom_point()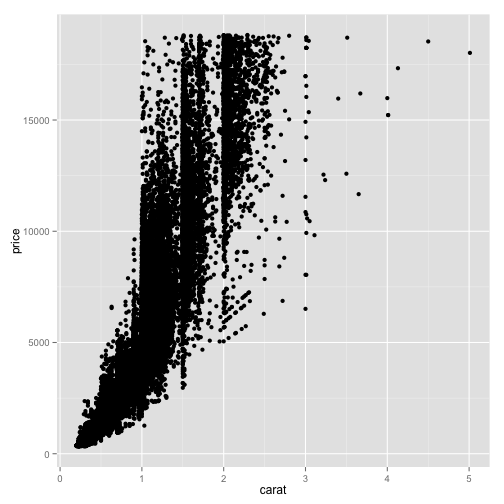
Now instead of displaying it, let's run that line again, but save it to a variable, called p.
p = ggplot(diamonds, aes(x=carat, y=price)) + geom_point()Note that when that happened, the plot did not get recreated: it WAS built but never displayed. We've saved the entire plot into this p object. Now we can save that plot to a file, instead of displaying it in our window, by using ggsave:
ggsave(filename="diamonds.png", p)## Saving 7 x 7 in imageWhat just happened is that we created a file called diamonds.png that saved the image. It doesn't have to be a PNG; it can also be a PDF:
ggsave(filename="diamonds.pdf", p)## Saving 7 x 7 in imageor a JPEG:
ggsave(filename="diamonds.jpeg", p)## Saving 7 x 7 in imageYou can read about the formats ggsave supports, and about the other options you can set like figure height and width, by doing help on ggsave:
help(ggsave)One useful shortcut is that if you just displayed a plot, like in a line like this:
ggplot(diamonds, aes(x=carat, y=price)) + geom_point()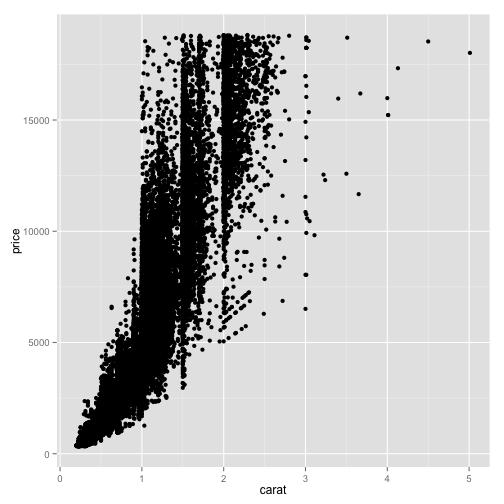
Then ggsave will know to save that plot by default when you perform ggsave- you don't even have to tell it which plot you're saving.
ggsave("diamonds.png")## Saving 7 x 7 in imageJust make sure you're saving the plot you mean to save.
Within RStudio, there's one other choice for saving a plot: you can click on Export, and then "Save Plot As Image," and then select your width, height, filename, and so on.