
This weekend three friends (Chris Riederer, Nathan Gould, and my twin brother Dan) and I took part in the 2017 TechCrunch Disrupt Hackathon. We’d all been to several of these hackathons before, and we enjoy the challenge of building a usable application in a short timeframe while learning some new technologies along the way.
Since three of the four of us are data scientists, we knew we were looking for a data-driven project, and since the best hackathon projects tend to be usable apps (as opposed to an analysis or a library) we figured we’d build a machine-learning driven product. We quickly landed on the idea of a classifier for the programmer community Hacker News, which would automatically assign topics to each submitted based on its text.
This project required scraping and downloading data, training a machine learning model, and turning it into a usable website in under 24 hours. Here I’m sharing some of the lessons we learned in the process.
(Note that I’m focusing on the data side since that’s what I worked on, but Nathan and Dan did great work in building and designing the site, as well as scheduling tasks to keep the site synchronized with Hacker News).
Retrieving Hacker News posts and articles
Hacker News collects articles submitted and upvoted by users, generally ones of interest to the programmer community (though not just articles about programming). Our task was to retrieve the text for each article and categorize it into one of a few topics.
We immediately knew we’d need a large amount of training data- perhaps tens of thousands of articles- for an algorithm to successfully identify topics on new stories. To do that we needed to scrape Hacker News for submitted stories and their links, then query each article to retrieve its text.
One mistake we made was relying on the Hacker News API to download submitted stories one at a time, which was a slow process that took hours to get 25,000 links. After the hackathon was over, we learned that there’s Hacker News dataset on Google BigQuery- after about twenty minutes of configuration I was able to download a million links. In the pressure of a hackathon, it’s hard to tell when to keep hunting for easy solutions like that as opposed to implementing something slow that you know will work (but that’s part of the fun).
Once we had the article links, we needed the text of each. This is challenging because these articles come from thousands of different websites in many different formats, but the python-goose package is designed for exactly this purpose. We divided this scraping up among three of our computers, at which point we were able to collect a couple thousand articles each hour. You can find our scraping code and some of our results in this GitHub repository.
Normally with a project like this we’d let a scraper run overnight, but of course that wasn’t an option! As the data started downloading, we split up into two teams: Nathan and Dan building the website, while Chris and I developed the machine learning algorithm on the data as it accumulated.
Developing a supervised training set
To train a supervised classifier you need a labeled set: articles where we knew the correct classification. We didn’t have nearly enough time to manually label examples ourselves (nor would we want to!). So how could we get a set of correctly labeled examples?
Well, if you flip through a few pages of Hacker News, you can realize that some titles tell you almost unambiguously what the topics are, even with simple pattern matching. Looking at the front page, articles like Why Amazon is eating the world is about Amazon, Why do many math books have so much detail and so little enlightenment? is about math, and Don’t tell people to turn off Windows Update is about Microsoft/Windows. We thus decided to create a training set based on regular expressions of article titles.
This process took some experimenting, including some exploratory analysis of common words and clusters in article titles. One of my favorite kinds of figures to create with words is a correlation network (see this chapter of our book Text Mining with R), and this was a good opportunity to better understand the data.
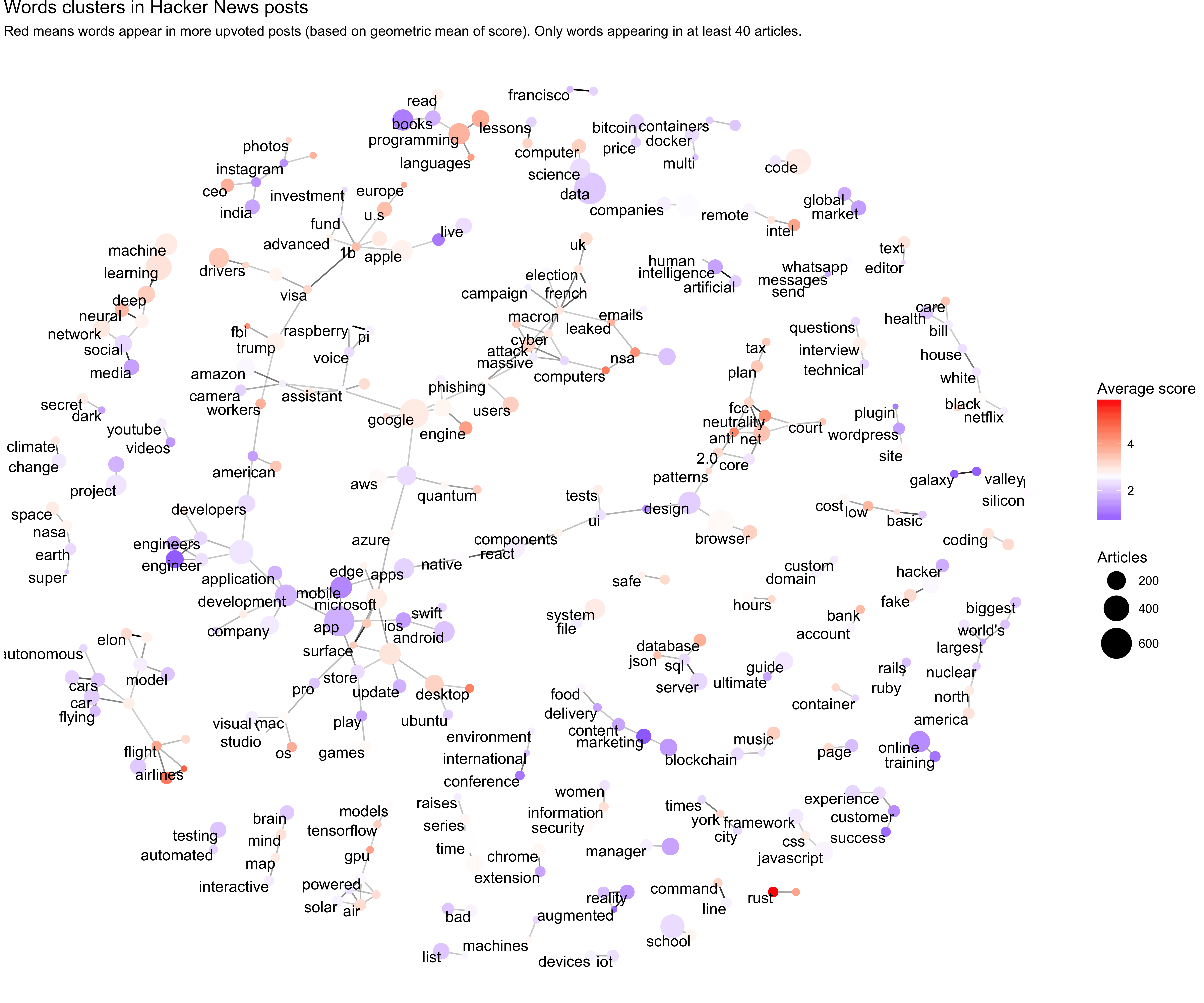
(I’m going to share some Hacker News analyses like this in more depth in future blog posts, especially now that we have much more data than we did during the hackathon). We notice clusters in the words, such as an ML cluster with “machine/deep learning” and various political clusters like “net/neutrality” and “trump/fbi”. This helped us concentrate on usable topics.
Here was the set of regular expressions we landed to train the model. This required a number of iterations and adjustments as we explored the resulting classifications, removing regular expressions that led to clear false positives and adding some that we’d missed.
| topic | regex |
|---|---|
| Python | python|pandas |
| Mobile | mobile|android|iphone|phone |
| Design | design |
| Security | security|worm|ransomware|attack|virus|patch|infosec |
| Blockchain | blockchain|bitcoin|ethereum |
| AI/Machine Learning | \bai\b|artificial intelligence|machine learning|deep learning|tensorflow|machine intelligence |
| Microsoft | microsoft|windows|visual studio |
| Apple | apple|mac\b|os ?x |
| Amazon | amazon |
| Startups | startup|\bvc\b |
| Politics | trump|comey|russian|fbi|snowden|neutrality|white house|government|brexit|nsa |
| Databases | sql|cockroachdb|mongodb|database|\bdb\b |
| Linux | linux|debian|ubuntu|centos |
| Data Science | data scien|big data|data vi|data ?set|data analy|machine learning|pandas|ggplot2 |
| Science | bio|drug|researcher|genomic|physics|scienti|spacex|\\bmoon\\b|nasa|\\bastro|\\bmars\\b |
| Math | math|geome|cryptograph|algebra|calculus |
fuzzyjoin in R makes it easy to match those to titles. You can find the code and some analyis behind it, as well as our machine learning work, in this repository.
We ended up with a training set of about 10,000 labeled documents (note that not all titles match any regular expressions, and some can match multiple). The breakdown of ones that match each regular expression was:
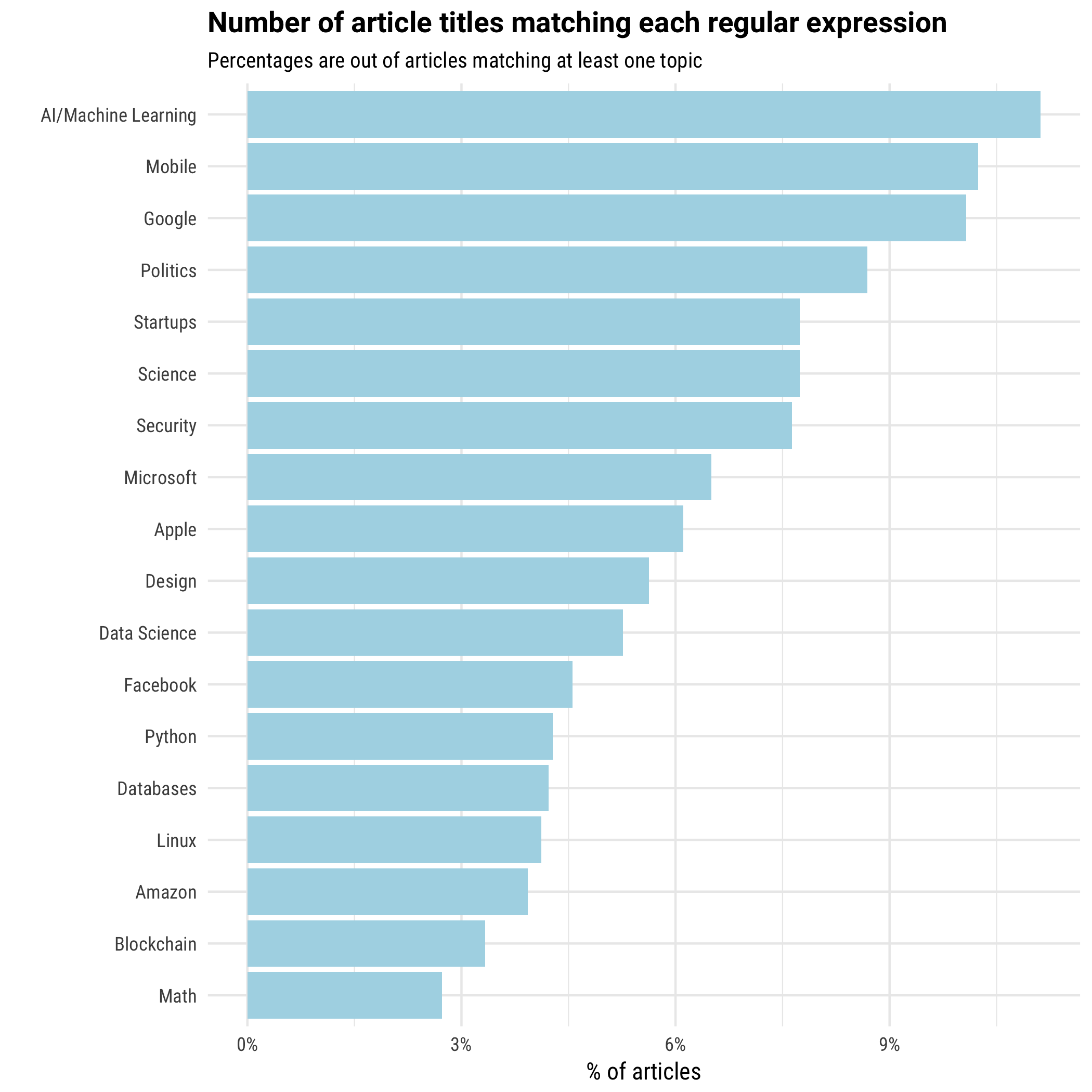
(We originally had a few other topics like “Web development” and “Javascript”, but ended up removing them based on the resulting classifications). Note that this doesn’t mean these are the most popular topics on the site! It’s based entirely on the regular expressions we decided on for each topic- if some topics are more recognizable from their titles than others, or if we made some oversights in coming up with these regular expressions, the article wouldn’t reflect that.
Using regular expressions on titles is a pretty crude way of capturing examples, and there’s no question that this adds biases and will not be entirely accurate (e.g. a title about “resizing windows” would be tagged as Microsoft). But it can be a fast and effective method for building a decently-sized training set, and manual inspection convinced us it was accurate enough.
Once we’d trained the algorithm on these titles, it was able to identify articles that didn’t have any of these telltale patterns in the title. For example, there’s nothing in the title Rejection Letter that suggests its topic, so it wasn’t in our training set. But because it contains words like “security”, “ransomware”, “antivirus”, and “worm”- words often occuring in articles in our training set- the algorithm easily tagged it as “Security”.
Training and productionizing an ML model
After we’d explored the data with R, we did our the machine learning with Python’s scikit-learn package. This took three steps:
- Tokenizing: We turned each article into a collection of words present in it, in a “bag of words” approach (we ignored the order and structure of the words).
- Dimensionality reduction: We used Latent Dirichlet Allocation, implemented by the (gensim Python package), to fit words into a topic model, turning each document into a vector of length 100. Each topic was fit from the d ata, associated with particular clusters of words (e.g. one topic could be highly associated with “trump”, “comey”, “russia” while another focuses on “design”, “photoshop”, “css”).
- Supervised classification: We used a supervised classifier to predict . We tried two: regularized logistic regression and random forests.
I’ve written on topic modeling before (it plays an important role in our text-mining book). Here, rather than using it to make conclusions, we were using it to reduce our tens of thousands of features (“this article contains the word ‘bitcoin’, this one doesn’t”) into a 100-dimensional dataset. Through some experimenting we found that adding this topic modeling step (as opposed to just using the words directly as features) improved our accuracy on the model.
We also saw that random forests beat logistic regression in terms of cross-validated AUC (area under the ROC curve) on our training set:
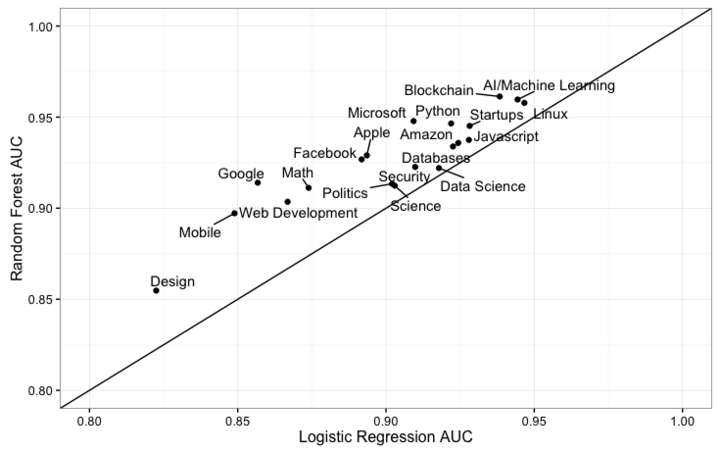
This fits with the general reputation around those models. Logistic regression is faster to train and a bit more interpretable, but isn’t as good at handling cases where many features interact. For example, it wouldn’t notice that the word “learning” means something different with the word “deep” than it would with “college” or “education.”
Of course, “accuracy” on this training set really just meant “could predict whether the article’s title matched the regular expression we thought it did”, but was our hope that this would translate to realistic predictions on new articles.
Productionizing a model
While Chris and I were building the model, Nathan and Dan had built the site with Django, deployed on Heroku, and registered a domain name. It synchronized with the Hacker News API every ten minutes, but as a placeholder assigned entirely random topics. Around 2 AM, once Chris and I had a trained model, it was time to combine our efforts.
In theory, building both the algorithm and the website in Python meant this would be straightforward, since we could slot it into directly into a function in the site. I’m accustomed to productionizing models by working with my team to convert from R to C#, so the ability to serialize models with pickle and load them directly into the app was certainly convenient, and let us be flexible with the model we implemented.
But this doesn’t mean deployment was painless! Two of the biggest hiccups we ran into were:
Using nltk on Heroku. We originally used the nltk library for tokenization, since it’s the most powerful toolkit for Python natural language processing. But it’s a large and cumbersome library, and we started running into obscure error messages on Heroku about installing and using it. For expediency, we ended up switching to the tokenizer built into gensim (which we already needed for topic modeling), which required retraining the algorithm.
Pickling between Python 2 and 3: We’d fit the model on Python 3, but because Goose, which we use for querying article text, isn’t Python 3 compatible, our production site had to be in Python 2. That was when we ran into this charming bug about pickling between Python 2 and 3.. It was 4 AM by then, and fixing required some pretty inelegant hacks.
We originally considered having the machine learning process as a microservice (a separate server that was passed text by the website and returned classifications). If we’d known the challenges we’d run into, we might have gone through with it. It would have made the handoff of a machine learning algorithm (giving the web team an API endpoint, rather than code and a list of package requirements) more painless.
Speaking and sharing
And with that, we had a live site at taggernews.com. We’ve changed the site a bit since, but when we submitted the project at 4:30 AM here’s what it looked like:
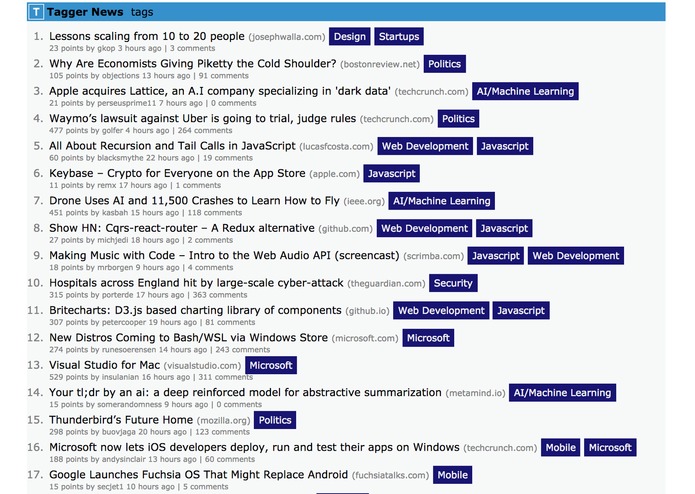
One thing I like about TechCrunch hackathons is that building the project is only part of the experience: we also had to “market” it. Our DevPost submission- required by 9:30 AM- consisted of a pitch for the product, a few images, and a short discussion of some of the challenges.
In the morning the participants all gave a one-minute demonstration of their projects to a crowd of participants. Chris did a great job in this pitch (enough to win us tickets to this week’s Disrupt conference). You can watch the video in the tweet below.
Tagger News automatically tags and sorts Hacker News articles #HackDisrupt pic.twitter.com/2mEbrGXIce
— TechCrunch (@TechCrunch) May 14, 2017
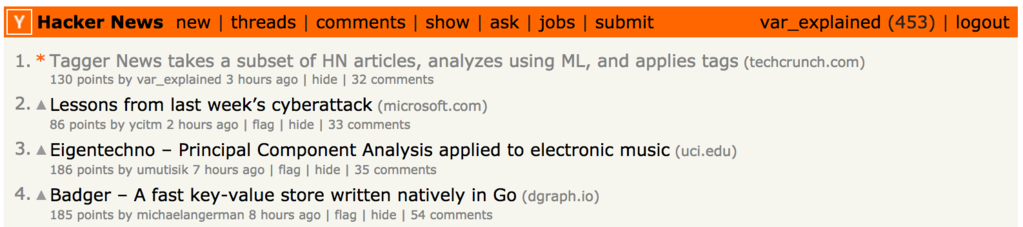
After the talk, TechCrunch interviewed us to write an article about our project, which in these hackathons was a first for us! After the hackathon was over, I decided to complete the circle and submit the TechCrunch article to Hacker News, and we were pleased to see that the community liked it:
We did well on ProductHunt today as well.
According to Google Analytics we got about 6,000 visitors to Tagger News yesterday, and they’re still coming. We were nervous about how the application would do with thousands of people trying it- we’d finished it at 4:30 AM and hadn’t had much time to test it. But outside of a few comments about the design and a couple inadvertently misclassified articles, the feedback was pretty positive! The site kept adding new stories, and for the most part they were correctly classified. It was a proof of concept, but a functional one, and it let us try out an interesting classification problem and put our approach into use.
And when people visited Tagger News, they got to see what kind of product it was:

Nailed it.