
I was amused by a Guardian article last month that declared “I’m a serious academic, not a professional Instagrammer,” arguing that social media is a distraction for scientific research. This attitude was, to say the least, not popular on academic Twitter, which responded with the #seriousacademic hashtag.
When someone tries to claim that a #seriousacademic should not use twitter... pic.twitter.com/ocL753NFSw
— Kitty Kat, PhD. (@academickitty) August 18, 2016
One part of the article that struck me as especially misguided was the author’s dismissal of conference tweeting:
I see more and more of them live tweeting and hashtagging their way through events…. When did it become acceptable to use your phone throughout a lecture, let alone an entire conference? No matter how good you think you are at multitasking, you will not be truly focusing your attention on the speaker, who has no doubt spent hours preparing for this moment.
I personally haven’t been a #seriousacademic in over a year, having since become a #sillydatascientist. So I felt no shame in live-tweeting the heck out of the two conferences I attended this summer: userR and JSM (Joint Statistical Meetings).
There’s a great analysis here of why people tweet during conferences. For me Twitter best serves as sort of “public diary”- I’m not very good at taking notes, and tweeting lets me create a record of what I found most interesting that I can refer to later. So as the summer ends, I’m looking back at my “notes” from these two conferences, and sharing my thoughts.
(If you’re a Serious Academic who is against live-tweeting of conferences, get out now, this post isn’t going to get any better.)
What I was up to at the conferences
At both conferences I gave a talk on my broom package for tidying model outputs. You can find the slides here, along with the useR video. I was especially impressed by the turnout for my talk at the useR conference, where I got to introduce broom to a large audience.
"Tidy data works until you start doing statistical modeling" – @drob (creator of awesome 'broom' package) #useR2016 pic.twitter.com/DGHwXIakFi
— Mikhail Popov (@bearloga) June 29, 2016
Slides from my #useR2016 talk yesterday are here: https://t.co/7brRt7eBV0 #rstats pic.twitter.com/24BOG0DHdl
— David Robinson (@drob) June 29, 2016
At JSM I also got to present an e-poster about some of the analysis of software developers I’ve done at Stack Overflow:
#JSM2016 folks: come see my e-poster on what @StackOverflow data tells us about landscape of software development pic.twitter.com/nkzcOYZsBK
— David Robinson (@drob) August 1, 2016
You can find the full slides here. The short version is that we can cluster programming languages based on which get used together:
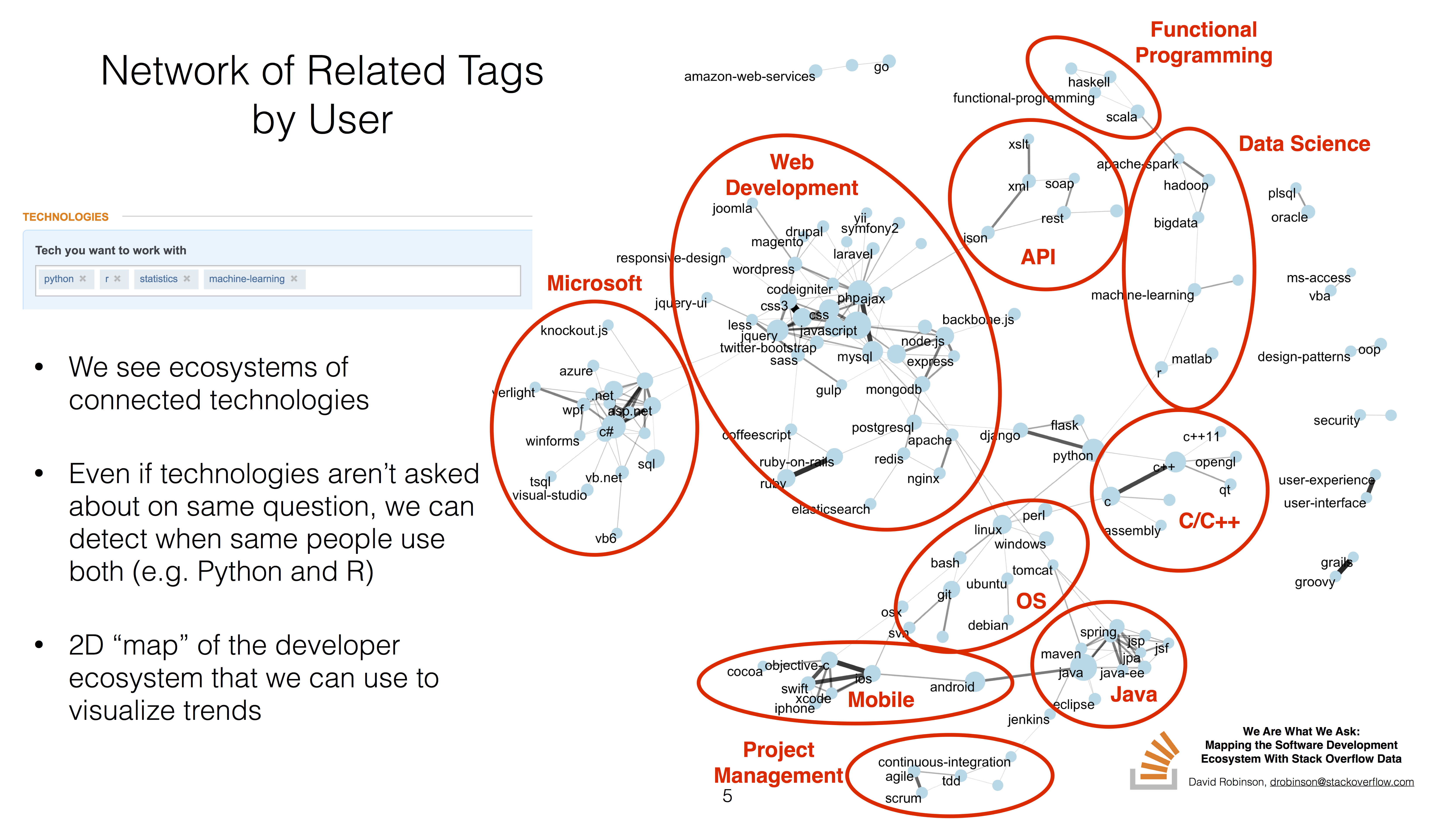
This also serves as a useful 2-dimensional layout for comparing technologies. For example, we could visualize which areas of the developer landscape are currently growing (red) or shrinking (blue), in terms of % of Stack Overflow questions:
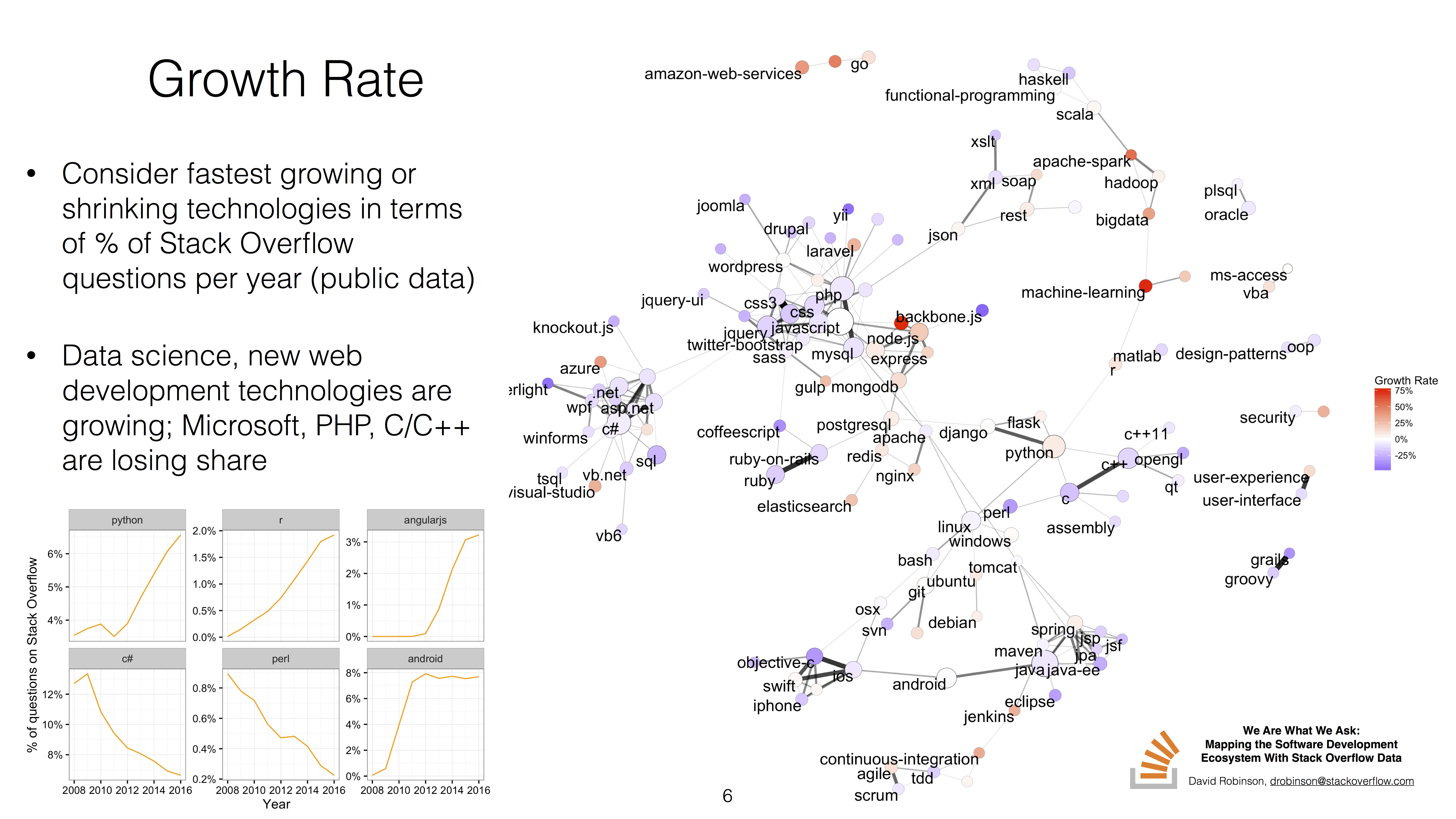
For instance, we can see that the data science cluster (including R and machine-learning) is growing in its share of Stack Overflow questions, while the C/C++ cluster below it is mostly shrinking.
Education
Many of my favorite talks were about data science education. This included my single favorite talk of either session- Deborah Nolan’s keynote address at useR on “Statistical Thinking in a Data Science Course” (video here):
Just imagine #stats course without simplified scenarios, canned data, non-coding, & always normal distrib #useR2016 pic.twitter.com/qsm7qT4rf2
— Alice Data (@alice_data) June 30, 2016
I’d heard these problems with statistical education described before, but never with this much clarity and evidence.
But alongside that talk, the talks about education at both conferences were uniformly excellent.
.@AmeliaMN shares an HS data science curriculum, including 400-page Introduction to Data Science doc. Wow! #useR2016 https://t.co/Czh2ViaaF4
— David Robinson (@drob) June 28, 2016
Some of the common themes included:
- That programming should be taught alongside statistics, and not as an afterthought- this was a nearly universal complaint among educators who have had to deal with statistics curricula.
- That students should be able to do powerful things immediately- many of the speakers focused on this point, and this is part of the foundation of my opinion that instructors should teach ggplot2 first. (Jeff Leek was also at JSM, where he doubled down on his dissenting opinion that plotting should be either difficult or ugly).
- That we should teach permutation and boostrapping rather than normal theory- this is a promising way to make statistics more intuitive and focus less on math early on. I did discuss with some people that this is a very frequentist approach to statistical education. What would be an equivalent math-lite Bayesian introduction?
"Randomize, Repeat, Reject"- Deborah Nolan suggests teaching permutation+bootstrap rather than normal theory #useR2016
— David Robinson (@drob) June 30, 2016
- That reproducible research should be a core part of education. This brings me to another great set of talks:
Reproducibility
Like much of the R community, I’ve internalized a lot of the lessons and practices of reproducible research. (For instance, these blog posts are reproducible from R markdown files in this directory)). But it was still great to hear people communicate these messages well, and the reproducibility session chaired by Amelia McNamara was an all-star cast.
.@minebocek makes an important point- requiring reproducibility makes work easier for students, not harder #JSM2016 pic.twitter.com/RU1CWHgbwy
— David Robinson (@drob) August 3, 2016
.@kwbroman's colleague was "sorry you did all that work on incomplete dataset"- reproducibility for the win #JSM2016 pic.twitter.com/cUTR2LRA1J
— David Robinson (@drob) August 3, 2016
Jenny Bryan talked about her and Ritz FitzJohn’s work on the jailbreakr package for reading warts-and-all Excel spreadsheets into R.
. @JennyBryan encouraging empathy for spreadsheet users as always #useR2016 pic.twitter.com/Nu5omprsW3
— Hilary Parker (@hspter) June 28, 2016
(This is something I’ve tried before but of which she and Ritz are the undisputed champions).
I particularly liked Yihui Xie’s idea about teaching reproducibility:
.@xieyihui had "evil" idea to teach reproducibility:
— David Robinson (@drob) August 3, 2016
Week 1: Students analyze a dataset
Week 2: "I updated the data, start over"#JSM2016
(Interestingly, a number of responses were along the lines of “How is that evil, that’s exactly what I’ve been doing!”)
In the same session, Karthik Ram from rOpenSci described JOSS, the Journal of Open Source Software. This is an excellent way to get citations and credit for software, and therefore for scientists to think of software packages (and not just papers) as units of research output.
.@_inundata promotes Journal of Open Source Software, w/ tidytext article by @juliasilge+me as example 🎉🎉 #JSM2016 pic.twitter.com/IOdF9Vt2hK
— David Robinson (@drob) August 3, 2016
Interactive Graphics
Many of my other favorite talks were about making online interactive visualizations.
Screw the dance party; after this #JSM2016 session I sorta want to spend tonight making interactive graphs #rstats pic.twitter.com/18otBYdgLP
— David Robinson (@drob) August 2, 2016
A lot of my knowledge about interactive graphics revolves around Shiny. Shiny’s a terrific tool, but it requires an R backend, which requires some effort and cost for deployment and scaling. I was excited to see what people were up to about building interactive graphics in R that could be deployed entirely in HTML and Javascript.
.@jcheng demos crosstalk #rstats pkg for interactive web graphs- define in R, deploy in Javascript. Wow! #JSM2016 pic.twitter.com/iyEwOBEiiJ
— David Robinson (@drob) August 2, 2016
Ryan Hafen’s rbokeh package is really exciting and something I hadn’t seen before (like others, I thought of Bokeh as a Python visualization package, but it turns out the backend is flexible). Since it plots in an HTML canvas it also doesn’t need an R backend, and I appreciated how the syntax used the %>% pipe and followed the grammar of graphics.
.@hafenstats trying 20 examples of rbokeh in 5 minutes https://t.co/EOWEfeFW0x #useR2016 pic.twitter.com/p2UWAEVqzj
— David Robinson (@drob) June 30, 2016
Carson’s Sievert has taken the “make ggplot2 interactive” conversation to a whole new level, though, with the plotly package, an R interface to the popular Plotly software that among other features includes conversion of ggplot2 objects into interactive plotly graphs.
Teaser for my #JSM2016 on interactive graphics with @plotlygraphs #rstats pic.twitter.com/koAqMg7t8j
— Carson Sievert (@cpsievert) August 1, 2016
I think Yihui Xie might have won the day, though. He not only led a terrific discussion of the previous talks (packed with GIFs, as is his habit), but also demonstrated a Shiny app that does something I’d never seen before in R:
.@xieyihui is customizing graphs with his voice and the room is Flipping. Out. #JSM2016 #rstats pic.twitter.com/HlFOL7rXGK
— David Robinson (@drob) August 2, 2016
.@xieyihui: "Change title to Make America Great Again", graph complies. Statistical applications are clear #JSM2016 https://t.co/1EhesE3s1D
— David Robinson (@drob) August 2, 2016
(Incidentally, I did end up going to the dance party, and still haven’t had the chance to use these interactive graphics for more than toy problems. Looking forward to the right opportunity to use them!)
RStudio
RStudio has been one of the most influential companies in the modern R world, not only developing the eponymous IDE but supporting many important open source packages, and the company was at both conferences in full force.
RStudio CEO J.J. Allaire talked about the new interactive notebook features of the RStudio IDE, analogous to Jupyter notebooks:
comparison betw R markdown & notebooks in JJ Allaire’s intro to @RStudio’s awesome new Rmd notebooks #UseR2016 pic.twitter.com/4QFp8hhBuu
— Karl Broman (@kwbroman) June 29, 2016
Hadley Wickham gave a useR keynote that pushed for a seismic shift in terminology:
.@hadleywickham proposes we stop saying "Hadleyverse", start saying "tidyverse" #useR2016 #rstats pic.twitter.com/Z4zs4tw2Vn
— David Robinson (@drob) June 29, 2016
He also stepped in for Yihui Xie to introduce Yihui’s terrific bookdown package:
The philosophy behind #rstats bookdown: easy, community-written, freq updated @hadleywickham + @xieyihui #useR2016 pic.twitter.com/WudsaLbHzY
— David Robinson (@drob) June 30, 2016
I was inspired enough by this package that one week later Julia Silge and I started writing the book Tidy Text Mining in R. Bookdown has been a real treat: it’s solved so many of the hassles around creating HTML and PDF manuscripts from knitr.
I was excited to meet RStudio’s Garrett Grolemund for the first time and talk statistics, education and R. He’s the creator of an awesome set of cheat sheets (available online) on R, and grabbing some hard copies at the RStudio booth was a nice bonus.
#useR2016 people: remember to stop by @rstudio booth to pick up awesome cheatsheets by @StatGarrett pic.twitter.com/9KWE9J416S
— David Robinson (@drob) June 30, 2016
Finally, I was crazy excited that RStudio had printed my first set of broom hex stickers:
@drob i have this for you! pic.twitter.com/8fpb2v738x
— Hadley Wickham (@hadleywickham) June 28, 2016
(The stickers are available on stickermule, and I’ll usually have some on hand at conferences and meetups if you run into me).
Accessibility
There are a lot of important ongoing conversations about diversity and inclusion in the R community (e.g. the TaskForce on Women in R, which presented on its findings at useR). But Jonathan Godfrey, a lecturer at Massey University in New Zealand, alerted me to another dimension of diversity I hadn’t considered before.
Jonathan Godfrey showing us how he uses a Braille keyboard to develop R code. Just amazing. #rstats #useR2016 pic.twitter.com/zYUFOeJXmY
— David Robinson (@drob) June 28, 2016
Dr. Godfrey is blind, and along with teaching and consulting on statistics, he develops some tools for helping vision impaired statisticians work with R, such as an in-progress e-book and the BrailleR package. One example of the BrailleR package is converting visualizations so that they could be understood by screen readers or Braille keyboards:
library(BrailleR)
x <- rnorm(1000)
VI(hist(x))## This is a histogram, with the title: Histogram of x
## "x" is marked on the x-axis.
## Tick marks for the x-axis are at: -3, and 3
## There are a total of 1000 elements for this variable.
## Tick marks for the y-axis are at: 0, 50, 100, and 150
## It has 12 bins with equal widths, starting at -3 and ending at 3 .
## The mids and counts for the bins are:
## mid = -2.75 count = 8
## mid = -2.25 count = 17
## mid = -1.75 count = 46
## mid = -1.25 count = 96
## mid = -0.75 count = 154
## mid = -0.25 count = 180
## mid = 0.25 count = 182
## mid = 0.75 count = 136
## mid = 1.25 count = 114
## mid = 1.75 count = 45
## mid = 2.25 count = 17
## mid = 2.75 count = 5Talking to him made me realize what great strides had been made in statistics and programming for the blind (here’s more on that general topic), but also what obstacles remained for R in particular. I take RStudio for granted, but according to Jonathan it’s effectively unusable for blind users (too many buttons, tabs and drop-down menus, which are difficult to navigate with a screenreader). Towards that goal he’s been working on the WriteR IDE for accessible programming in R and R markdown:
Jonathan Godfrey talks WriteR: IDE accessible to blind. Looking for Python-savvy volunteers to contribute #useR2016 pic.twitter.com/HEYum541jE
— David Robinson (@drob) June 29, 2016
(You can find the video of his talk on WriteR, and on the pitfalls of markdown for blind users, here).
I also asked him about the topic of data sonification to replace visualization for blind scientists. Jonathan was very skeptical- among other issues, he pointed out that sight and sound often provide different but complementary channels of information, which is the reason sighted statisticians can find sonification useful. He also noted that he often works with at least one sighted collaborator, so there’s still an opportunity for visualization to surprise someone in ways a model cannot. I don’t know much about the topic and I wonder if there are other perspectives.
People
Probably my favorite part of visiting a conference is the people I got to see, whether meeting them for the first time or seeing them again.
Table of #useR2016 folks, chatting, as one does, about how much fun it is to be called Dr. pic.twitter.com/goxtTlmNcE
— David Robinson (@drob) July 1, 2016
Aside from the people I’ve already mentioned (and many others), it was great to meet up with the Hopkins/ex-Hopkins Biostatistics crowd.
Four statisticians setting up an eposter
— David Robinson (@drob) July 31, 2016
"Does anyone know how to use Windows?"#JSM2016 @jtleek @acfrazee @hspter pic.twitter.com/d1hfD4ElBi
Hilary Parker chaired an excellent session on data science in industry. I missed Jeff Leek’s talk since mine was at the same time, but our feud did make an appearance in his slides:
😄😄😄 @jtleek s/o to @drob and the actual reasons people use methods #JSM2016 pic.twitter.com/gRHXYgEbjh
— Hilary Parker (@hspter) August 1, 2016
I'm OK with this analogy from @jtleek's talk because I get to be Batman #rstats #JSM2016 pic.twitter.com/nBpoW7qunx
— David Robinson (@drob) August 4, 2016
I was happy to see my former colleague Chee Chen present at JSM on work he and I had done together:
Rather than defining 1 p-value threshold for FDR control, fFDR has threshold vary w/informative variable Z #JSM2016 pic.twitter.com/HQAUAyRrPG
— David Robinson (@drob) August 4, 2016
And see my former adviser John, who has always been a compelling statistical communicator.
This slide by @johnstorey sets great example for math presentation- graphics help audience follow equations #JSM2016 pic.twitter.com/svDULAXZyc
— David Robinson (@drob) August 1, 2016
Among the new people I got to meet were Amelia McNarama and Craig Citro, who gave me a run for my money at talking quickly:
fast_talking_R_mafia <- c(" @drob", "@AmeliaMN", "@craigcitro")#User2016 pic.twitter.com/jLrAzRiPrM
— Karthik Ram (@_inundata) July 1, 2016
There were so many other people and so many other talks I could have mentioned here (if you scroll through my twitter feed under #JSM2016 and #useR2016 you’d see a lot more). Overall I’m very glad I attended both, and that I had the chance to learn from and contribute to the great R and statistics communities. And I’m glad I wasn’t too #serious to share that.
Story of how I once was a #seriousacademic, but Twitter turned me into a #sillydatascientist https://t.co/QGZRJbOUZM
— David Robinson (@drob) August 5, 2016