
In January, I was excited to make an announcement about a shift in my career:
I have some exciting news: today I'm joining @DataCamp as their Chief Data Scientist 🎉📊📈 pic.twitter.com/wiN9J4qSjx
— David Robinson (@drob) January 29, 2018
When I first discussed the role with the DataCamp CEO, I described my goal as to “Make DataCamp as good at doing data science as we are at teaching it.” Now that I’ve settled in, I’d like to talk about my plans in that direction (and to make a pitch for coming to work with us as a data engineer!)
Why I joined DataCamp
I loved working at Stack Overflow for two and a half years. I got to work with great web developers and data engineers to develop product features and to spread the tools and philosophy of data science throughout the company. I’ve been especially delighted to write about my data analyses in posts on the company blog.
But I’m very excited about this next step in my career. Part of the reason I’m excited to join DataCamp can be summarized by a graph I made last year for the Stack Overflow blog. Visits to Stack Overflow questions give us terrific insight into what programming technologies are growing and shrinking, based on how many visits go to particular tags. In a series of posts I took a look at the fastest growing tags on the site:

The two technologies that singularly stand out are R and Python. While Python can be used for many types of applications, in another post I showed that most of the growth in Python can be credited to data science. In short, data science is the fastest-growing part of the programming ecosystem. And as it grows, someone has to take responsibility for teaching the newcomers, whether they’re a beginner starting a data science career or an engineer or analyst interested in keeping up with data science skills.
This tells me that DataCamp is the right place to be, because nobody is better at teaching R and Python for data science. We have 77 live courses in R and 33 in Python (along with courses in complementary skills like SQL, shell, and git), and that content library is growing every week. And the focus on interactive exercises in the browser makes us uniquely suited to helping students learn.
Educating the next generation of data scientists is deeply important to me. I’ve worked with DataCamp as an external instructor before, teaching courses like my introduction to the tidyverse, foundations of probability, and a case study in exploratory data analysis. I’ve also written before about why I recommend teaching ggplot2 and the rest of the tidyverse as an introduction to R. I think that doing data science DataCamp is where I can contribute the most towards this goal.
How do we do data science at DataCamp?
To understand the Chief Data Scientist role, it’s worth sharing a bit about how data science is organized at DataCamp. The structure of data science within an organization has been the topic of a lot of discussion recently (Jacqueline Nolis has some of my favorite writing on the topic, including this presentation from Data Day Texas, and I’ve found the O’Reilly book Creating a Data-Driven Organization has helpful stories on how different companies structure it).
We have an extraordinary team of data scientists here, and one important decision we made when I joined is that in most cases they don’t report to me. Michael Chow is a learning engineer on my team that develops models and product features for measuring student learning, but other data scientists are spread through the company, each on a cross-functional team. For instance, we have a data scientist on the finance team (Dennis Vandevenne) who develops dashboards and analyses for sales and customer success. Ramnath Vaidyanathan leads research on the product team. And just this week my sister Emily Robinson joined the growth team to work on A/B tests and perform deep analyses of user acquisition. Each data scientist reports to the head of that department and focuses on that team’s problems, but also has a regular meeting with me and with the group to discuss the work they’re doing and the data-related challenges we’re having. In turn I report to the CEO and keep a birds-eye view of how data science works at the company.
As an individual contributor: “I have to go to a meeting this afternoon so today’s shot to hell”
— David Robinson (@drob) March 22, 2018
As a team lead: “Oooh what a treat I’ve got 1-1:30 PM all to myself”
This is generally referred to as matrix management, and it keeps data scientists close to the problems they’re working on and the priorities of their team. Perhaps my favorite advantage is that other managers can decide what data scientists should work on, which lets me focus on the how. This means the business stakeholders themselves get to spend time prioritizing projects, and I get to do my favorite task of helping data scientists do awesome things.
As you can probably imagine, there are challenges in this model (for instance, data scientists have to go to more meetings, and it’s hard to reallocate data effort across teams when necessary), but as of now I’m very optimistic about its future. I’ll likely write more about my thoughts on matrix management and data science in a future post.
What does a Chief Data Scientist do?
I previously wrote about what a data scientist does, but my responsibilities have changed with the new role. What do I now spend my time on?
Developing data science tools and processes. Since I have a global perspective on what data scientists at the company need, I work on building internal tools that help all our data scientists analyze our data. Perhaps the most important task is maintaining an internal R package, called datacampr, that manages connecting to our internal data sources. This was one of my favorite parts of working as an individual data scientist at Stack Overflow, so I’m excited that it’s become central to my work.
Similarly, another challenge is to surface work that data scientists have done so that the whole company can benefit from it. Towards that goal I’ve launched an internal knowledge repository, using AirBnb’s open source Knowledge Repo project. This lets data scientists contribute articles that everyone at the company can browse and understand, which helps reduce duplication of effort.
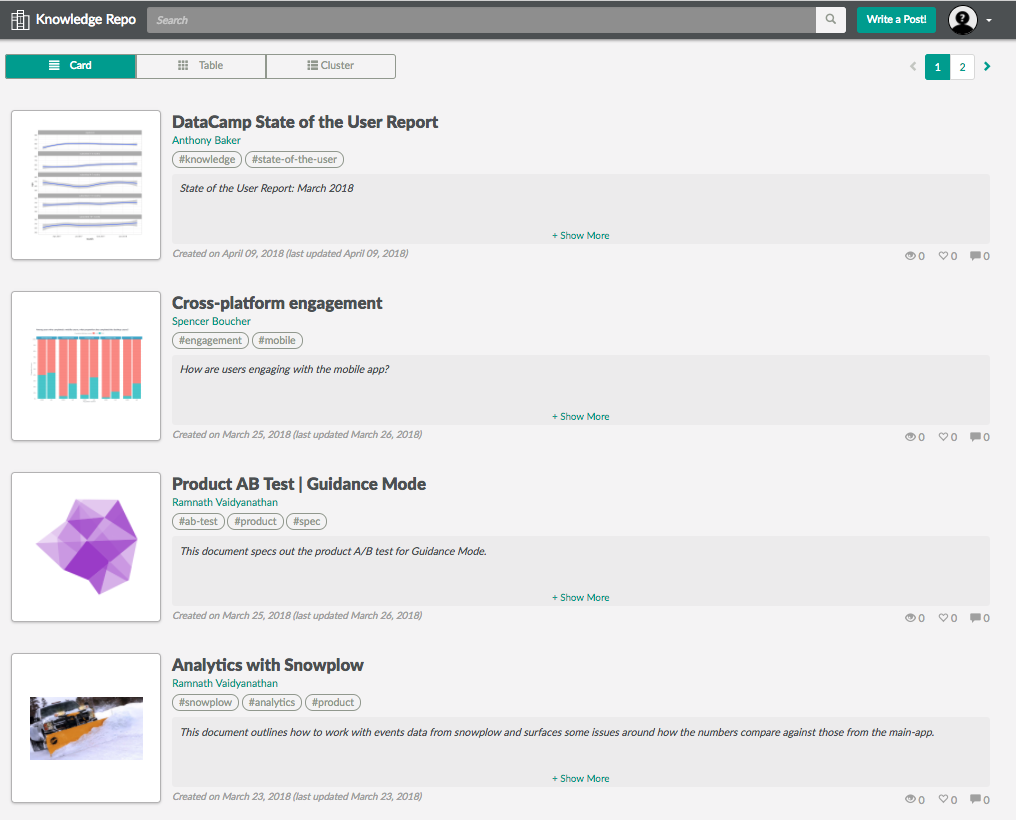
I’ve open sourced some of my work in the knowledgerepo R package, an R client for submitting articles to a knowledge repo. I’m hoping to share more of what I’ve learned in the future.
Meetings and advising: As a team that shares functional expertise, it’s useful for us to meet and compare notes on the challenges we’re having (“I’ve noticed these tables are slow to query: how could we index them to be faster?”). This lets data scientists share solutions (“oh, I have a query for that”) and lets me keep an eye on what tools and processes need to be built. It’s also fun to talk shop to other data scientists in the company- this week Ramnath shared an awesome open source project he’s working on (once it’s public you’ll probably be excited too!)
I also have weekly meetings individually with each data team member to help with whatever they’re analyzing or building. Sometimes that means pair programming, sometimes it means looking into eccentricities of our data, and sometimes it means following up with other teams to fix blocking issues. Since I share a background in data science, I’m often in a better position to handle data-related problems than their manager is. I also set up meetings to help people outside the team for whom understanding data is a part of their work, and I have some plans for making that a more formal part of my responsibilities.
While I often joke (like in the tweet above) about going to more meetings than I used to, the truth is that I really enjoy working with other people to help them understand data. Collaboration was one of my favorite parts of graduate school, and it’s been one of my favorite parts of being part of the larger data science community. There are other benefits as well:
The best part about being an Architecture Lead is helping other people code. That way it's their name in git blame.
— Nick Craver (@Nick_Craver) August 31, 2017
Manage data engineering: Data engineering has a close relationship with data science, since it’s responsible for making our data fast and easy to access. DataCamp uses a microservice architecture running on AWS (here’s an article from our CTO describing the vision), and our data sources are now large enough to require careful consideration in terms of how we store and query them.
Our engineering team believes strongly in ownership (the idea that each part of our infrastructure should have someone clearly responsible for it), and this extends to data science. In particular, we’ve taken a lot of inspiration from Jeff Magnusson’s Engineers Shouldn’t Write ETL that data scientists should be in charge of their own business logic in data pipelines, while data engineering is responsible for the platform. For example, data scientists often want to define their own views, stored queries that can be queried like a SQL table. We’ve recently implemented a system where data scientists can create their own views, each materialized once a day, just by pushing a file to a GitHub repository.
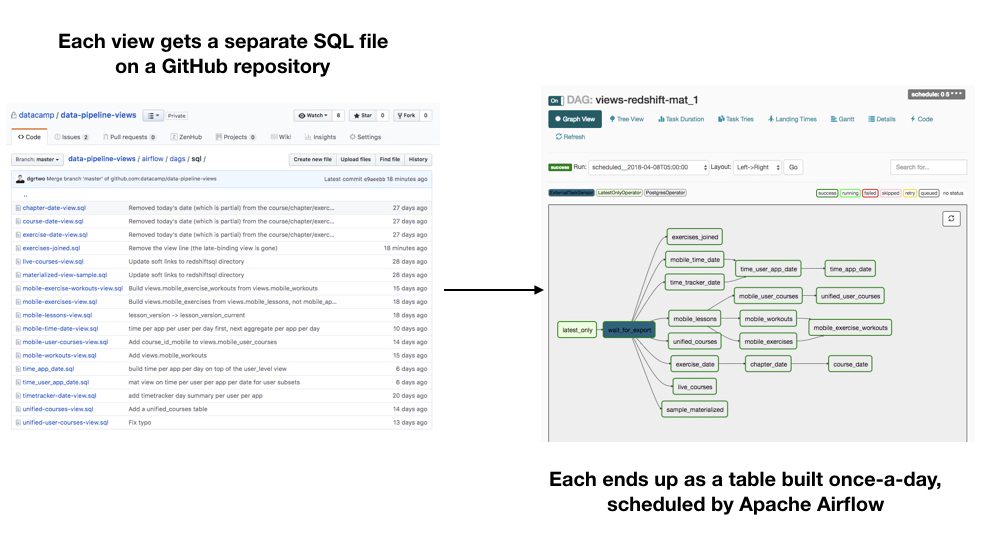
This kind of process is useful to data scientists, because it makes the infrastructure side (maintaining databases, scheduling tasks) invisible and let them focus on the SQL and business logic. In turn, if a view breaks or needs to be changed, the data scientist can take full responsibility for fixing it: they don’t need to go through anyone else. As I describe below, there’s a lot more work to be done on systems like this.
What’s next
Now that I’m a bit settled in, I’ve started planning what the rest of the year of data science at DataCamp will look like.
-
Hiring a data engineer. I’ve worked with consultants and our engineering team to develop infrastructure like I described above, but we don’t have a data engineer and I’m not qualified to take the next steps in building our data pipeline. That’s why we’re currently hiring for our first data engineer (working in Python), who’ll report to me and take over these responsibilities. It’s a chance to work closely with data scientists and lead the development of a powerful data platform. Please apply or get in touch if you’re interested!
-
Supporting Python within the company. Most of my tool development has been focused on R, since that’s what most of the data science team prefers for our analyses. But we have a ton of Python data science talent in the company as well (for instance, several people on the content team), and as we hire in the future we’d like to make it a truly “bilingual” data science department. In the next few months I’ll be bringing some of our Python data science infrastructure up to speed so that analysts have their choice of how to work.
-
Sharing what we’ve learned. DataCamp has access to extraordinary data about how people learn data science. Hundreds of thousands of people have learned R through our interactive introductory course, and for every exercise we have hundreds of thousands of attempted submissions. This means we have a particularly rich dataset around what people try, including what kinds of mistakes learners make.
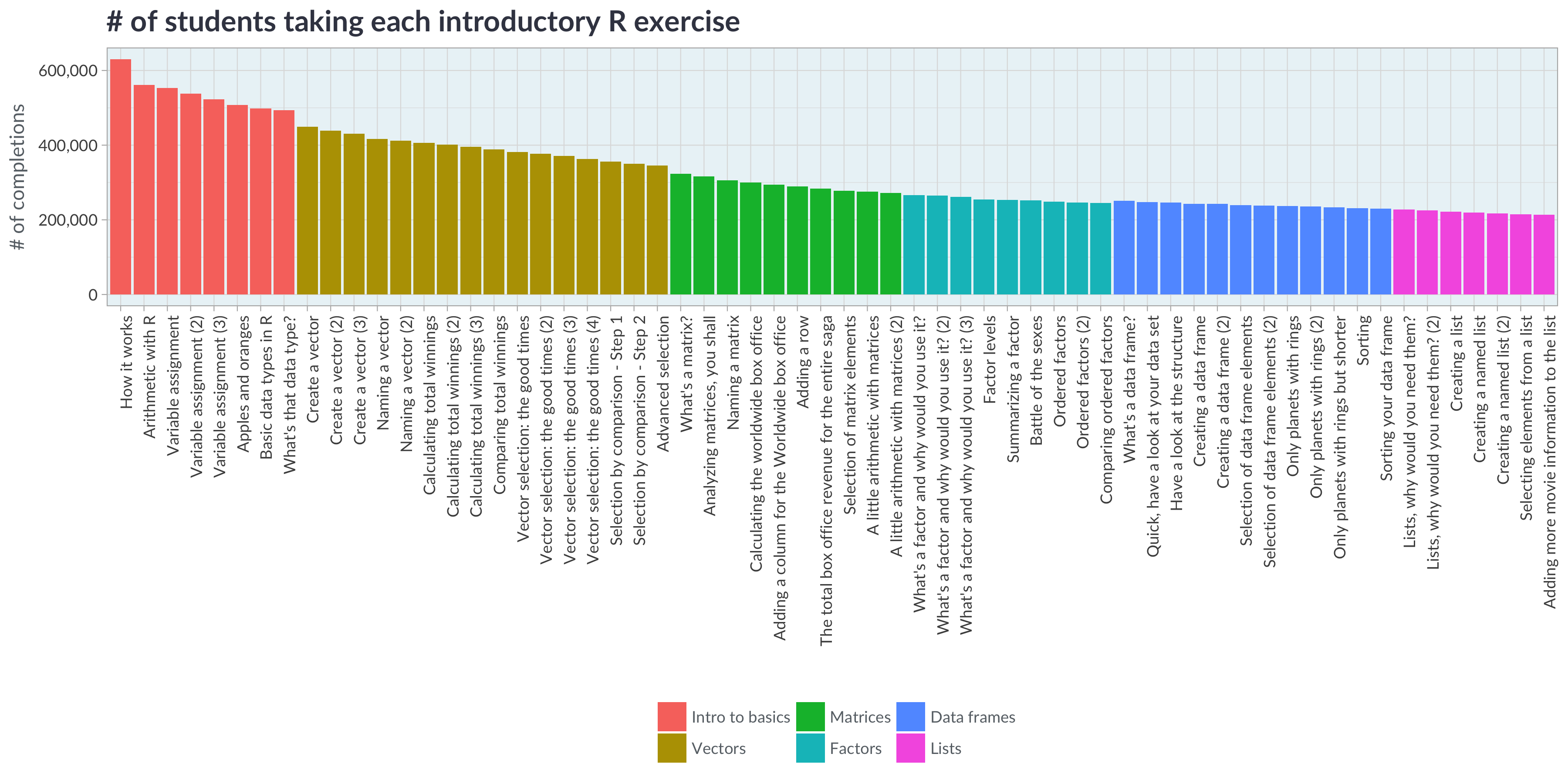
One of my favorite parts of being a data scientist is sharing my results publicly. In the coming months my team and I will be sharing some blog posts about what we’ve learned from our learners, and how we’ve used these analyses to improve our platform and remain the best way to learn data science.